


The first generation of coding assistants mostly stayed outside the repository. They could answer questions, explain code, and generate diffs, but the actual work still came back to the developer. Someone had to apply the change, run the command, check the failure, and decide what happened next.
As assistants became agents, tools like Aider, Cursor, and Claude Code gave models access to the repo, the filesystem, and the terminal. This did remove a lot of friction: if the agent already knew what to edit and which test to run, it could close the loop itself.
But giving agents the ability to act also changed the risk. Shell access is useful for running tests and installing dependencies, but it can also execute destructive commands, expose sensitive files, or follow malicious instructions hidden in the repo. Permissioning helped, but allowlists and approval prompts could only go so far. Shell safety is contextual, and the same command can be harmless in one situation and dangerous in another.
Long-running workflows like Ralph loops and later claw systems made this more obvious. Developers wanted agents that could keep working beyond a single prompt: try an approach, run tests, inspect failures, update code, and continue. That kind of autonomy needs more than tool access. It needs a safe, persistent place to work.
While building Potpie, we ran into the same issue. There were no agent specific isolation systems that catered to the quirks of agent specific permissions. Docker, spare machines, allowlists, and remote sandboxes each solved part of the problem, but each left something unresolved: persistence, privacy, recovery, scale, and lastly trust.
That is why coding agents need an agent-native sandbox: A sandbox with a safer but permissive shell, a controlled workspace where they can work freely enough to be useful without putting the host, the codebase, or any other systems at risk.
Agent-native sandbox: A sandbox is more than an execution layer
Traditionally, a sandbox has been seen as a secure place to execute shell commands. That is part of it, but for coding agents, it is not enough. A coding agent needs three things to stay separate: the repository, the workspace and the execution environment.
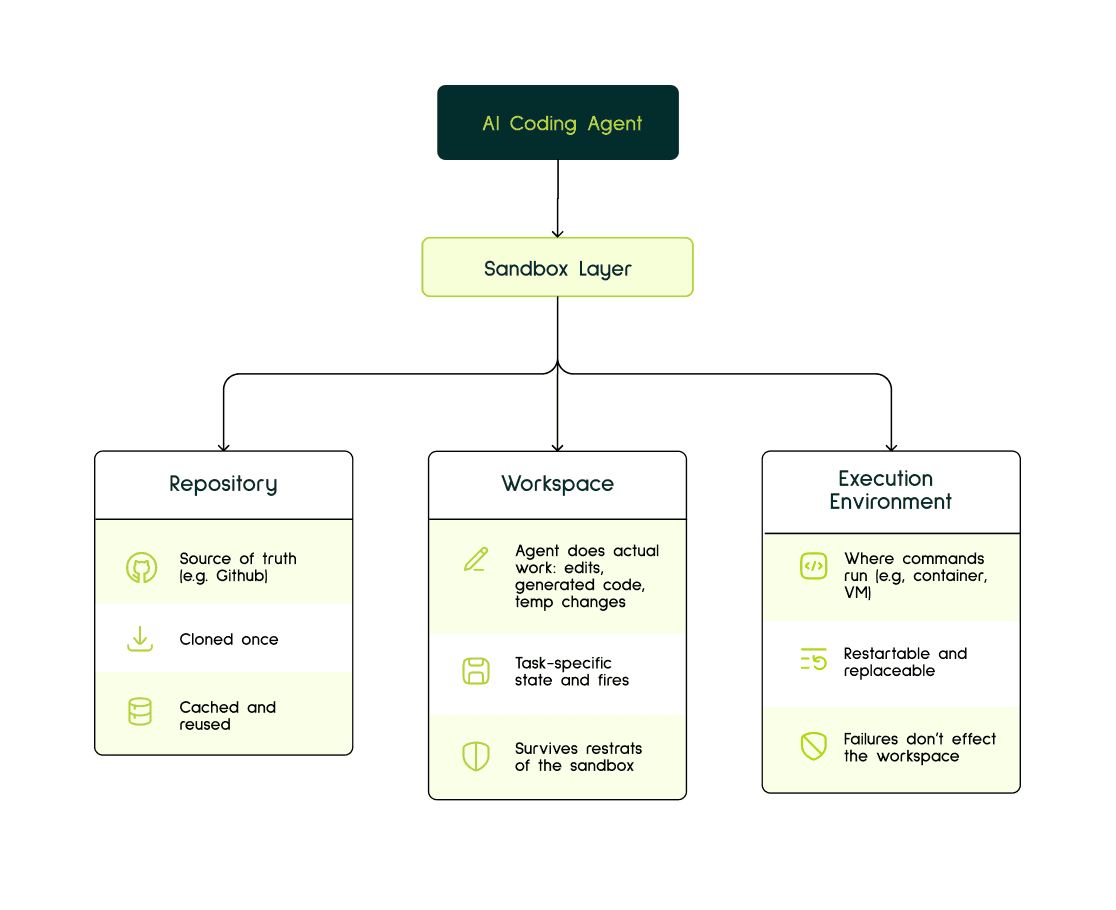
The repository (eg: GitHub), is the source of truth. It should be cloned once, cached, and reused.
The workspace, like a local project folder, is where the agent does its actual work: edits, generated code, temporary changes, and task-specific state. If the agent session or command runner restarts, this should not disappear.
The execution environment is a virtual system where the commands run. The virtual environments can be LXC containers or VMs of any kind. The main requirement for these systems is they can maintain statefulness allowing for easy restart and replacement without taking the workspace down with it.
When these layers are tied too closely together, small failures become costly. A container restart should not erase edits, and a broken command runner should not force the agent to rebuild its context from scratch. Agents also introduce failure modes that normal execution environments were not designed around: long-running loops, partial edits, repeated retries, tool failures, prompt-injection risk, and state that needs to survive across sessions. So it is imperative a sandbox should separate durable workspace state from disposable execution, and is designed around the way agents actually work.
Agentic workflows need stronger isolation
Before AI agents, most code execution was still human-mediated. A developer reviewed the command, ran the script, approved the dependency, or checked the CI output.
Agents changed that.
They write code dynamically, install packages, run commands and follow instructions from files, issues and tool outputs. They may get it right, hallucinate a step, or read something malicious without realizing it.
This is why isolation matters.
A sandbox creates a boundary between the agent’s execution environment and the rest of your system. If the agent runs a bad command, installs a suspicious dependency or gets tricked by a prompt injection hidden in a README, the damage should stay contained. It should not touch your host machine, your production systems or another team’s workspace.
Isolation can also take more than one form. File system boundaries, network controls, secret handling, environment variable access, and outbound request policies are all part of the same problem. For example, some agent platforms are starting to treat credentials as something the agent should not see directly, even when the task needs access to a tool or service. LangSmith’s approach to hiding environment tokens points in this direction: the agent can use what it needs without being handed every secret in plain text.
As the agent runtime matures, these boundaries should become more explicit and more configurable. Teams should be able to decide what the agent can read, where it can connect, which secrets it can use indirectly, and what parts of the environment are completely off-limits. The important part is that these controls should not be bolted on as one-off decisions for every task. They should be part of the sandbox model itself.
For local development, this sandbox can simply be a container. Containers are fast, practical and easy to spin up, which makes them a good default for coding agents. But the broader idea is the same regardless of the backend: the agent needs an isolated place to work.
As teams scale, the isolation boundary needs to get stronger. A local container may be enough for one developer, while larger teams will eventually want managed sandboxes, shared infrastructure or stronger VM-like isolation. The infrastructure should be able to grow with the team.
Not every team needs a self-contained sandbox from day one. But every coding agent needs a safe execution boundary from the start.
Stable sandbox accelerates the agent workflow
In less tool-native setups, agents end up relying heavily on prompts for file edits. If they need to change a file, they have to pull file contents into context, reason over them, generate a diff and hope the patch applies cleanly. That burns tokens and makes edits more fragile.
With a stable write-capable workspace, the agent does not need to describe every file operation in the prompt. It can use tools directly.
The flow is simple: the agent works inside the sandbox, makes changes, runs checks, and returns the result as a diff, branch, or pull request. From there, the engineering workflow takes over: review, CI, approval, and merge. If the same task needs more work later, the agent can return to that environment. If not, it can be cleaned up.
This boundary matters. The agent gets a safe place to edit, test, search the repo, run commands, and prepare commits, but production code still moves through the usual controlled process.
This improves the efficiency of the agent loop. The model can focus more on the task instead of wasting context on moving file contents around.
This follows the same pattern as Potpie’s knowledge graph approach: agents work better when they can query structure instead of blindly searching through raw text, and when they retrieve only the code they actually need instead of pulling entire files into context.
The guarantees that matter
A sandbox system for coding agents should keep a few promises.
The repository should not be re-cloned for every task. If the repo has already been cloned and cached, the agent should use that cached version. Re-cloning wastes time, bandwidth, and compute.
The workspace should survive restarts. If an execution process dies or a sandbox is evicted, the agent’s edited files should still be there.
Execution should be replaceable. A broken command environment should not destroy repository state or workspace state.
State should be tracked explicitly. Database-backed state tracking matters because resume, cleanup, eviction, and lifecycle management need to be honest. The system should know which repo is cached, which workspace belongs to which task, which backend is active, and what can be safely cleaned up.
Without this knowledge, sandbox recovery becomes guesswork. And guesswork is exactly what you do not want in infrastructure that is supposed to let agents work autonomously.
Parallel Sandboxes: From safe execution to faster experimentation
Once sandboxes become cheap and reliable, you do not have to think of them as one agent working in one environment. You can run multiple isolated sandboxes at the same time.
One sandbox can try one implementation branch. Another can try a different approach. A third can run tests or check for regressions. None of them pollute each other’s workspace, and the system can compare the results before deciding what to keep.
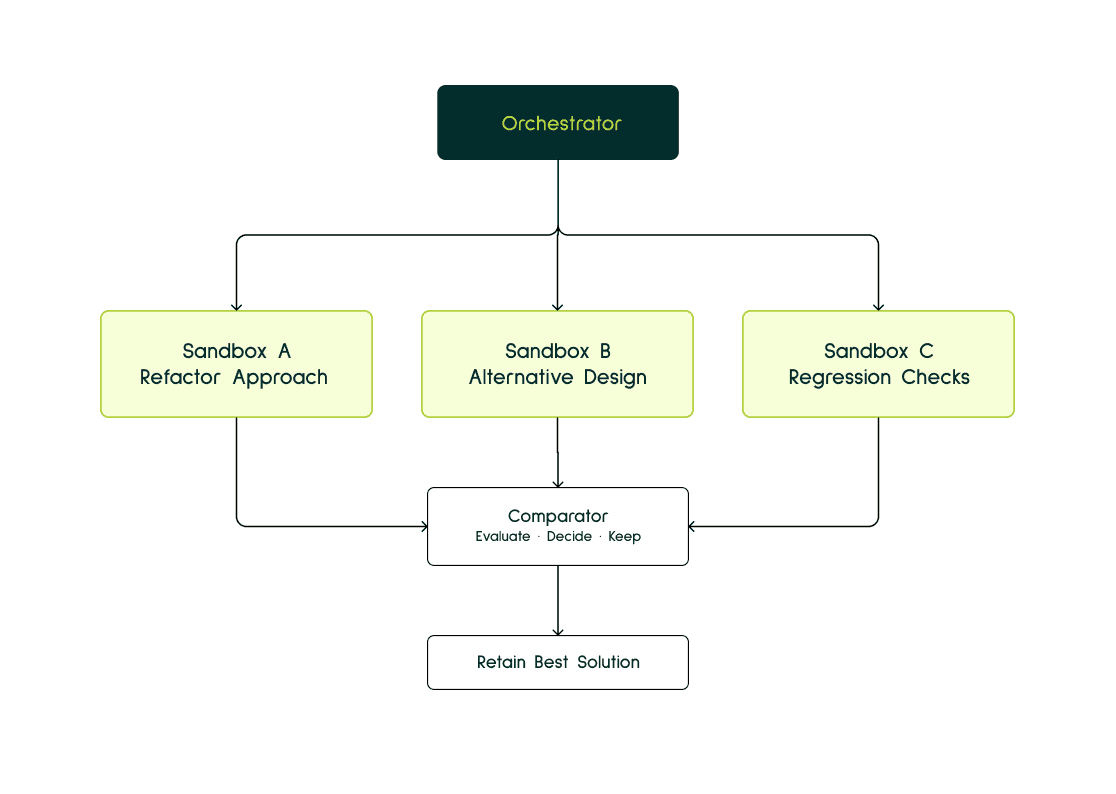
This matters because software work is often exploratory. There are usually multiple ways to fix a bug, refactor a module or design an API. Parallel sandboxes let agents try those paths side by side instead of one after another.
This is where sandboxing stops being just a safety layer. It becomes a way to make agents faster, more reliable and less afraid to experiment.
Why Containers work locally, but do not solve everything
For local development, a containerized sandbox is the obvious starting point.
Docker is the most familiar version of this. It is quick to spin up, easy to clean up and gives enough isolation without adding the overhead of a remote setup. Since everything runs locally, latency between the agent and the sandbox is minimal. Commands execute fast and file changes feel instant.
The important part is that the container is write-capable. Modern coding agents are not just answering questions anymore. They are modifying files, creating branches, running tests, and validating changes. They need a workspace they can actively work in.
For an individual developer or a medium-sized repo, this works well. But once teams start running many agents, working with larger repositories, or delegating heavier tasks, the developer’s machine becomes a bottleneck. Your laptop should not be the limiting factor deciding whether an agent can finish a long-running refactor.
That is why the sandbox backend needs to be pluggable.
Making Sandbox backend pluggable by design
Once local containers stop being enough, the temptation is to pick one self-contained sandbox backend and build everything around it.
That works for a while, but it does not scale across different teams. A small team may care most about fast local execution. A larger team may need stronger isolation. Enterprises may need shared storage and persistent remote workspaces that are not tied to a single developer’s machine.
So the agent should be agnostic to the sandbox underneath. Docker can be the fast local default, Daytona can handle managed remote sandboxes, NFS can support teams running many agents at scale, and E2B can slot in as another managed backend when needed.
The agent should talk to one clean interface. The backend becomes a deployment choice, while the agent logic stays stable.
From Supervision to Delegation
The sandbox may look like a backend detail. For coding agents, it becomes part of the agent contract. It defines where edits live, how commands run, what state survives, which secrets are available, and what should happen when execution fails. Those details matter because the agent works across a longer chain of actions: reading tool output, making partial edits, retrying failed steps, installing dependencies, and sometimes continuing through long-running loops.
That is why the sandbox has to be designed around agent-specific failure modes. If the runtime disappears, the workspace should remain intact. If a command environment breaks, it should be possible to replace it without losing the task. If a workflow needs stronger isolation, the backend should be able to change without forcing the agent logic to change with it. The system should handle this complexity in the sandbox layer, where workspace state, execution, and access can be managed deliberately.
Docker, Daytona, NFS, and E2B are useful because they answer different parts of this architectural requirement. One team may need fast local execution, another may need persistent remote workspaces, and another may care most about stronger isolation or shared storage. A stable sandbox interface keeps the agent logic independent from those deployment choices, while the backend is selected based on the task, the team, and the level of isolation required.
Once that layer exists, delegation changes shape. Developers can define the boundary the agent operates inside: what it can access, where it can run, what state is durable, and how failures are recovered. The agent gets a consistent place to work, and the system keeps that work contained enough to be trustworthy.
" height="176.48689063250688px" id="t2zO9Quc7" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="1.55" stroke="rgb(180, 209, 63)" transform="translate(0.773 0.758)" width="307.0499654602649px"/></svg>)
" height="127.83155915492955px" id="F7uNl9dyd" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(8.021 100.549)" width="136.10429429577454px"/><path d="M 120.738 0 L 166.541 2.512 L 302.646 81.116 L 259.995 105.741 L 140.463 174.742 L 48.783 121.822 L 39.844 116.65 L 21.917 106.308 L 4.359 96.162 L 0 69.714 Z M 84.883 90.646 L 93.847 95.818 L 111.75 106.16 L 140.734 122.881 L 155.534 97.468 L 158.883 91.73 L 212.812 81.264 L 161.197 51.467 L 141.177 39.918 L 130.096 46.32 L 124.653 49.473 L 69.099 81.535 Z M 27.753 84.712 L 130.096 25.635 L 146.718 16.031 L 130.096 15.292 L 26.472 75.132 Z" fill="rgb(0, 53, 51)" height="174.74215475179432px" id="XL4eRTHOZ" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(3.647 4.386)" width="302.6461113816823px"/><path d="M 0 0 L 0 10.343 L 16.622 0.739 Z" fill="rgb(0, 53, 51)" height="10.34275225352113px" id="cBwRaCSIs" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(133.76 19.669)" width="16.622023943661958px"/><path d="M 0 59.84 L 1.28 69.419 L 103.623 10.343 L 103.623 0 Z" fill="rgb(0, 53, 51)" height="69.41898253521126px" id="yI1DYW3PI" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(30.132 19.669)" width="103.62314999999992px"/><path d="M 0 0 L 0 49.251 L 14.357 57.55 L 17.706 51.812 L 71.636 41.346 L 20.021 11.549 Z" fill="rgb(0, 53, 51)" height="57.54972676056339px" id="swIgz6ZQs" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(144.827 44.294)" width="71.63555704225351px"/><path d="M 0 41.617 L 15.785 50.728 L 24.748 55.9 L 42.651 66.242 L 72.078 49.251 L 72.078 0 L 60.997 6.403 L 55.555 9.555 Z" fill="rgb(0, 53, 51)" height="66.2424190140845px" id="Ou0foMTnv" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(72.761 44.294)" width="72.07816690140838px"/><path d="M 0 93.626 L 0 142.877 L 162.183 49.251 L 162.183 0 L 119.532 24.626 Z" fill="rgb(0, 53, 51)" height="142.87681267605637px" id="F6Glizjhy" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(144.11 85.495)" width="162.1830021126761px"/><path d="M 0 0 L 0 49.251 L 4.359 75.699 L 4.359 26.448 Z" fill="rgb(0, 53, 51)" height="75.69868943661974px" id="CEJbzDHVA" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(3.661 74.105)" width="4.358684366197165px"/></svg>)
" height="275.2348071827544px" id="tOCVqXAMo" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.05" stroke="rgb(180, 209, 63)" transform="translate(2.023 1.876)" width="306.08189403973506px"/></svg>)
" height="272.22086421478906px" id="PPsuL8gM9" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.04" stroke="rgb(180, 209, 63)" transform="translate(2.016 1.798)" width="306.4324539473682px"/></svg>)
" height="176.48689063250686px" id="YZ_qP17EP" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="1.55" stroke="rgb(180, 209, 63)" transform="translate(0.773 0.758)" width="307.04996546026496px"/><g d="M 62.549 28.787 C 62.536 28.761 62.526 28.736 62.519 28.709 C 62.535 28.768 62.56 28.824 62.6 28.878 C 62.578 28.849 62.562 28.818 62.549 28.787 Z M 62.549 28.787 L 62.6 28.878 C 62.56 28.824 62.535 28.768 62.519 28.709 Z M 54.656 27.136 L 53.678 29.273 C 52.829 31.129 53.725 33.105 56.041 34.482 L 67.491 41.285 L 70.928 43.27 C 73.406 44.7 77.049 45.237 80.421 44.654 L 121.141 37.611 C 120.159 39.696 120.291 41.929 121.582 44.003 C 125.001 49.499 120.112 55.555 110.627 57.574 C 105.569 58.649 101.585 60.95 99.722 63.869 C 96.226 69.347 85.734 72.169 76.215 70.194 C 71.142 69.142 65.525 69.424 60.847 70.967 C 52.07 73.864 40.885 72.132 35.787 67.087 C 33.07 64.398 28.45 62.529 23.146 61.975 C 13.195 60.934 6.552 55.458 8.262 49.704 C 9.172 46.637 7.711 43.493 4.263 41.1 C -2.205 36.611 -1.202 29.951 6.515 26.18 C 10.627 24.17 13.008 21.221 13.03 18.11 C 13.07 12.271 21.254 7.547 31.367 7.524 C 36.757 7.511 41.866 6.135 45.347 3.761 C 50.795 0.044 59.728 -0.975 67.055 0.959 Z M 121.101 29.063 C 121.295 29.225 121.319 29.421 121.365 29.811 C 121.437 30.422 121.416 31.043 121.303 31.658 C 121.245 31.973 121.216 32.132 121.07 32.303 C 120.952 32.442 120.731 32.596 120.516 32.689 C 120.25 32.804 119.941 32.858 119.324 32.965 L 78.041 40.112 C 77.569 40.193 77.056 40.118 76.707 39.917 L 73.268 37.93 C 72.552 37.516 72.859 36.812 73.828 36.645 L 118.972 28.911 C 119.692 28.787 120.052 28.726 120.384 28.774 C 120.655 28.814 120.941 28.93 121.101 29.063 Z M 77.422 5.057 L 85.829 15.345 L 85.834 15.352 C 85.944 15.485 85.999 15.553 86.076 15.611 C 86.144 15.664 86.226 15.711 86.317 15.751 C 86.42 15.796 86.54 15.83 86.779 15.895 L 107.021 21.407 L 107.041 21.413 C 107.775 21.613 108.144 21.713 108.236 21.838 C 108.316 21.947 108.297 22.073 108.187 22.173 C 108.059 22.288 107.655 22.352 106.863 22.48 L 64.254 29.318 C 63.803 29.4 63.362 29.338 63.037 29.193 L 62.989 29.169 C 62.826 29.09 62.694 28.987 62.61 28.87 L 62.559 28.779 L 62.529 28.701 C 62.501 28.597 62.509 28.489 62.561 28.376 L 73.706 5.239 L 73.713 5.226 C 74.151 4.315 74.371 3.857 74.769 3.71 C 75.115 3.582 75.548 3.562 75.927 3.654 C 76.364 3.761 76.717 4.193 77.422 5.057 Z" fill="transparent" height="72.36999344346039px" id="PThBnjLXo" transform="translate(95.525 49.205)" width="122.67217843649964px"><path d="M 0.03 0.077 C 0.017 0.052 0.007 0.027 0 0 C 0.016 0.059 0.041 0.115 0.081 0.169 C 0.059 0.139 0.043 0.109 0.03 0.077 Z" fill="rgb(180, 209, 63)" height="1px" id="FZhYXbO6L" transform="translate(62.519 28.709)" width="1px"/><path d="M 62.549 28.787 L 62.6 28.878 C 62.56 28.824 62.535 28.768 62.519 28.709 Z M 54.656 27.136 L 53.678 29.273 C 52.829 31.129 53.725 33.105 56.041 34.482 L 67.491 41.285 L 70.928 43.27 C 73.406 44.7 77.049 45.237 80.421 44.654 L 121.141 37.611 C 120.159 39.696 120.291 41.929 121.582 44.003 C 125.001 49.499 120.112 55.555 110.627 57.574 C 105.569 58.649 101.585 60.95 99.722 63.869 C 96.226 69.347 85.734 72.169 76.215 70.194 C 71.142 69.142 65.525 69.424 60.847 70.967 C 52.07 73.864 40.885 72.132 35.787 67.087 C 33.07 64.398 28.45 62.529 23.146 61.975 C 13.195 60.934 6.552 55.458 8.262 49.704 C 9.172 46.637 7.711 43.493 4.263 41.1 C -2.205 36.611 -1.202 29.951 6.515 26.18 C 10.627 24.17 13.008 21.221 13.03 18.11 C 13.07 12.271 21.254 7.547 31.367 7.524 C 36.757 7.511 41.866 6.135 45.347 3.761 C 50.795 0.044 59.728 -0.975 67.055 0.959 Z M 121.101 29.063 C 121.295 29.225 121.319 29.421 121.365 29.811 C 121.437 30.422 121.416 31.043 121.303 31.658 C 121.245 31.973 121.216 32.132 121.07 32.303 C 120.952 32.442 120.731 32.596 120.516 32.689 C 120.25 32.804 119.941 32.858 119.324 32.965 L 78.041 40.112 C 77.569 40.193 77.056 40.118 76.707 39.917 L 73.268 37.93 C 72.552 37.516 72.859 36.812 73.828 36.645 L 118.972 28.911 C 119.692 28.787 120.052 28.726 120.384 28.774 C 120.655 28.814 120.941 28.93 121.101 29.063 Z M 77.422 5.057 L 85.829 15.345 L 85.834 15.352 C 85.944 15.485 85.999 15.553 86.076 15.611 C 86.144 15.664 86.226 15.711 86.317 15.751 C 86.42 15.796 86.54 15.83 86.779 15.895 L 107.021 21.407 L 107.041 21.413 C 107.775 21.613 108.144 21.713 108.236 21.838 C 108.316 21.947 108.297 22.073 108.187 22.173 C 108.059 22.288 107.655 22.352 106.863 22.48 L 64.254 29.318 C 63.803 29.4 63.362 29.338 63.037 29.193 L 62.989 29.169 C 62.826 29.09 62.694 28.987 62.61 28.87 L 62.559 28.779 L 62.529 28.701 C 62.501 28.597 62.509 28.489 62.561 28.376 L 73.706 5.239 L 73.713 5.226 C 74.151 4.315 74.371 3.857 74.769 3.71 C 75.115 3.582 75.548 3.562 75.927 3.654 C 76.364 3.761 76.717 4.193 77.422 5.057 Z" fill="rgb(180, 209, 63)" height="72.36999344346039px" id="AQyCIziS7" transform="translate(0 0)" width="122.67217843649964px"/></g></svg>)
" height="150.90560294117645px" id="jxii70vzV" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(24.37 4.791)" width="261.37546588235216px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.728 3.018 L 116.384 4.988 L 123.793 7.455 L 130.373 10.224 L 136.629 13.481 L 142.286 17.103 L 147.097 20.91 L 151.356 25.179 L 154.784 29.643 L 157.336 34.117 L 159.104 38.936 L 159.995 43.657 L 159.981 48.672 L 159.104 53.438 L 157.336 58.222 L 154.784 62.73 L 151.356 67.194 L 147.128 71.41 L 142.286 75.271 L 136.629 78.892 L 130.373 82.149 L 123.686 84.945 L 116.384 87.386 L 108.728 89.356 L 100.843 90.838 L 92.557 91.859 L 84.164 92.374 L 75.632 92.365 L 67.439 91.859 L 59.322 90.865 L 51.344 89.365 L 43.611 87.386 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.464 L 8.639 67.194 L 5.227 62.775 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.782 L 0.892 38.936 L 2.613 34.25 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.37355058823529px" id="LN6Mj2wjX" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.05 69.207)" width="159.99511058823543px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.729 3.018 L 116.383 4.988 L 123.794 7.455 L 130.374 10.224 L 136.63 13.481 L 142.287 17.103 L 147.098 20.91 L 151.357 25.179 L 154.785 29.643 L 157.337 34.117 L 159.103 38.936 L 159.996 43.657 L 159.979 48.672 L 159.103 53.438 L 157.337 58.222 L 154.785 62.73 L 151.357 67.194 L 147.129 71.41 L 142.287 75.271 L 136.63 78.892 L 130.374 82.149 L 123.687 84.946 L 116.383 87.385 L 108.729 89.355 L 100.843 90.838 L 92.557 91.858 L 84.164 92.374 L 75.632 92.365 L 67.439 91.858 L 59.322 90.864 L 51.344 89.364 L 43.611 87.385 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.463 L 8.639 67.194 L 5.227 62.775 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.781 L 0.892 38.936 L 2.613 34.25 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.37427764705882px" id="jDPtsCydt" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.76 83.833)" width="159.99583764705716px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.728 3.018 L 116.384 4.988 L 123.793 7.455 L 130.373 10.224 L 136.629 13.481 L 142.286 17.103 L 147.097 20.91 L 151.356 25.179 L 154.784 29.643 L 157.336 34.117 L 159.104 38.936 L 159.995 43.657 L 159.981 48.672 L 159.104 53.438 L 157.336 58.222 L 154.784 62.73 L 151.356 67.194 L 147.128 71.41 L 142.286 75.271 L 136.629 78.892 L 130.373 82.149 L 123.686 84.945 L 116.384 87.386 L 108.728 89.356 L 100.843 90.838 L 92.557 91.859 L 84.164 92.374 L 75.632 92.365 L 67.439 91.859 L 59.322 90.865 L 51.344 89.365 L 43.611 87.386 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.464 L 8.639 67.194 L 5.227 62.775 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.782 L 0.892 38.936 L 2.613 34.25 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.37355058823529px" id="UKafYhxUp" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.05 69.207)" width="159.99511058823543px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.728 3.018 L 116.384 4.988 L 123.793 7.455 L 130.373 10.224 L 136.629 13.481 L 142.286 17.103 L 147.097 20.91 L 151.356 25.179 L 154.784 29.643 L 157.336 34.117 L 159.104 38.936 L 159.995 43.657 L 159.981 48.672 L 159.104 53.438 L 157.336 58.222 L 154.784 62.73 L 151.356 67.194 L 147.128 71.41 L 142.286 75.271 L 136.629 78.892 L 130.373 82.149 L 123.686 84.945 L 116.384 87.386 L 108.728 89.356 L 100.843 90.838 L 92.557 91.859 L 84.164 92.373 L 75.632 92.365 L 67.439 91.859 L 59.322 90.865 L 51.344 89.365 L 43.611 87.386 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.463 L 8.639 67.194 L 5.227 62.775 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.781 L 0.892 38.936 L 2.613 34.25 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.3733688235294px" id="BTS7eFR5p" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.05 48.404)" width="159.99511058823543px"/><path d="M 128.886 85.255 L 0 105.189 L 0 19.934 L 128.886 0 Z" fill="transparent" height="105.18923470588237px" id="XpYvdAzW3" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(57.724 4.311)" width="128.88608117646865px"/><path d="M 92.835 53.589 L 92.835 138.028 L 0 84.439 L 0 0 Z" fill="transparent" height="138.02757352941174px" id="K8lS4_UO3" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(192.202 5.927)" width="92.8345058823547px"/><path d="M 30.371 77.481 L 0 142.926 L 0 65.41 L 30.371 0 Z" fill="transparent" height="142.92631411764705px" id="ckGqTr2MB" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(21.656 34.705)" width="30.37088294117827px"/><path d="M 30.371 77.481 L 0 142.928 L 0 65.411 L 30.371 0 Z" fill="transparent" height="142.9275864705882px" id="r3233RfUB" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(254.683 70.769)" width="30.371064705883697px"/><path d="M 92.835 53.589 L 92.835 138.027 L 0 84.439 L 0 0 Z" fill="transparent" height="138.02721000000003px" id="LSrhVSYKp" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(21.656 104.548)" width="92.83486941176557px"/><path d="M 128.886 85.255 L 0 105.19 L 0 19.934 L 128.886 0 Z" fill="transparent" height="105.18959823529411px" id="x2Xopuli2" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(120.064 138.931)" width="128.88626294117825px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.728 3.017 L 116.384 4.988 L 123.793 7.455 L 130.373 10.224 L 136.629 13.481 L 142.286 17.103 L 147.097 20.91 L 151.356 25.179 L 154.784 29.643 L 157.336 34.116 L 159.104 38.936 L 159.995 43.657 L 159.981 48.672 L 159.104 53.438 L 157.336 58.221 L 154.784 62.73 L 151.356 67.194 L 147.128 71.41 L 142.286 75.271 L 136.629 78.892 L 130.373 82.149 L 123.686 84.945 L 116.384 87.385 L 108.728 89.356 L 100.843 90.838 L 92.557 91.859 L 84.164 92.373 L 75.632 92.364 L 67.439 91.859 L 59.322 90.865 L 51.344 89.365 L 43.611 87.385 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.463 L 8.639 67.194 L 5.227 62.774 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.781 L 0.892 38.936 L 2.613 34.249 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.3733688235294px" id="dtqTIoHPq" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.05 30.156)" width="159.99511058823543px"/></svg>)
" width="309px"><path d="M 0 0 C 62.424 52.356 97.323 76.699 124.122 133.612 C 125.774 137.121 129.275 139.414 133.153 139.414 L 178.332 139.414 C 182.27 139.414 185.824 137.027 187.434 133.433 C 220.347 59.939 255.786 56.508 309 0 C 223.902 11.24 92.218 13.79 0 0 Z" fill="rgb(244, 255, 200)" height="139.41414141414143px" id="YPPdTHgjp" width="309px"/></g></svg>)
" width="291.547144895145px"><path d="M 2.159 40.336 L 81.816 193.109 C 85.087 199.382 91.575 203.316 98.649 203.316 L 199.157 203.316 C 206.445 203.316 213.09 199.143 216.257 192.578 L 289.654 40.384 C 294.95 29.401 288.66 16.33 276.702 13.944 C 186.518 -4.05 102.962 -5.096 14.535 13.537 C 2.503 16.072 -3.526 29.434 2.159 40.336 Z" fill="rgb(174, 218, 0)" height="203.31595618278868px" id="beF0XCFO6" transform="translate(0 0)" width="291.54714489452647px"/></g></svg>)
" width="279.949712674067px"><path d="M 1.851 35.23 L 64.467 192.416 C 68.34 202.139 77.749 208.518 88.214 208.518 L 194.612 208.518 C 205.187 208.518 214.67 202.007 218.469 192.138 L 278.208 36.927 C 285.378 18.296 269.348 -1.055 249.578 1.717 C 168.185 13.131 109.4 10.303 29.167 0.211 C 9.712 -2.236 -5.406 17.013 1.851 35.23 Z" fill="rgb(145, 181, 0)" height="208.51809526570761px" id="tGoxWLGVd" transform="translate(0 0)" width="279.94971259877605px"/></g></svg>)
Recommended Blogs






























