


Introducing Potpie: AI Agents Built on Deep Code Understanding
Potpie is an open-source platform that brings AI agents to every stage of the software development lifecycle. What sets Potpie apart is its foundation: rather than treating code as flat text, Potpie constructs comprehensive knowledge graphs of entire repositories, capturing relationships between functions, classes, dependencies, and architectural patterns.
These knowledge graphs power intelligent inference engines that give AI agents true contextual awareness. When debugging an issue or implementing a feature, Potpie's agents form a deep understanding of how code flows through your system, maps code components, and intelligently figures out where changes might have cascading effects.
This graph-based approach enables agents to tackle complex SDLC tasks like automated testing, debugging, code analysis, and feature development with the kind of holistic understanding that typically requires deep familiarity with a codebase. By building rich semantic representations of codebases and layering agentic workflows on top, Potpie bridges the gap between traditional static analysis and modern AI-powered development.
Understanding SWE Bench: The Gold Standard for Coding Agents
SWE Bench has emerged as one of the most rigorous and widely-adopted benchmarks for evaluating AI coding agents. Unlike synthetic coding challenges, SWE Bench presents a unique proposition: real-world GitHub issues pulled from popular open-source repositories.
The benchmark works by evaluating whether an agent can generate file diffs that successfully resolve actual issues developers have faced. Each instance includes the original issue description, the repository context, and a test suite that validates whether the fix actually works. Agents are scored by applying their generated diffs to the codebase and running these pre-defined tests.
SWE Bench Lite, the most commonly referenced variant, contains 300 carefully curated instances spanning several prominent Python repositories including Django, Pylint, Matplotlib, and Scikit-learn. What makes this benchmark particularly challenging is that it requires agents to understand complex codebases, navigate real-world code patterns, and produce fixes that don't break existing functionality, mirroring the actual constraints software engineers face daily.
Potpie Custom Agents for the WIN !!!
For us, SWE-bench is more than just a metric, it’s a reality check. It’s where we prove that our graph-based approach to code understanding isn't just a cool theory, but a powerful tool that actually solves the messy, complex problems real developers face every day. If an agent can fix issues in Django's ORM or debug Pylint's AST parser, it demonstrates genuine understanding of complex codebases, not just pattern matching on toy examples.
This is where Potpie's Custom Agents shine. SWE Bench challenges require a specialized debugging workflow that's quite different from everyday features like generating new features or writing documentation. With Custom Agents, we can:
Define task-specific instructions that guide the agent toward root cause analysis rather than superficial patches
Shortlist relevant tools from Potpie's toolkit: ode search, dependency analysis, test execution is tailored to debugging workflows
Encode debugging strategies like "explore the call chain," "check edge cases," or "verify assumptions with tests"
Iterate rapidly on prompts and tool selection without rebuilding core infrastructure
For our SWE Bench agent, we've built a Custom Agent specifically optimized for the debugging loop: understand the issue, explore relevant code through the knowledge graph, hypothesize root causes, generate targeted fixes, and validate with tests.
What It Takes to Solve SWE Bench: Requirements and Reality
Fixing real-world GitHub issues requires far more than just chaining API calls together. It’s an exercise in high-level engineering that demands the same intuition and precision an experienced developer brings to a debugging session. When you move from a human engineer to an orchestrated AI agent, you aren't just solving a technical puzzle, you’re navigating a whole new frontier of execution and logic.
Key Challenges
Meeting these requirements in practice surfaces four critical challenges:
Thinking Like a Software Engineer
Solutions are rarely well-defined in the issue description
Must identify and fix underlying problems, not just surface symptoms
Handle edge cases that may not be explicitly mentioned
Make decisions about the cleanest, most maintainable way to solve the problem
Reason about code quality, architecture, and potential side effects
Context Engineering
Agents may run for extended periods, processing tens of thousands of tokens
At any point, the LLM must receive concise, precise tasks with exactly the relevant information
Too much context leads to information overload and degraded performance
Too little context means missing critical details needed to solve the problem
Managing this attention budget is crucial for success
Managing Trade-offs
Knowing when to stop exploring and commit to a solution
Choosing between multiple plausible fixes
Deciding how much time to spend on reproduction vs. patch generation
Balancing thoroughness against resource constraints
These meta-decisions about resource allocation directly impact success rates
Meeting All Requirements Simultaneously
Every requirement must be satisfied—there's no partial credit
Agent might correctly identify the bug, navigate to the right file, and generate valid code, but miss a subtle edge case
Or produce a fix that solves the immediate problem but breaks an unrelated test
Missing even one requirement means complete failure on that instance
Core Requirements
A debugging agent needs four fundamental capabilities:
Codebase Exploration
Navigate unfamiliar repositories efficiently
Traverse call chains and dependency relationships
Discover relevant code sections that may be hundreds of files away from the bug's surface symptoms
Codebase Intelligence
Understand both syntax and semantics: builds deep understanding of how components interact, what invariants exist, where side effects propagate
Leverage knowledge graphs to build contextual awareness of the entire system
Structured Analysis
Follow systematic debugging workflows: reproduce the problem, form hypotheses, test assumptions
Validate fixes against the issue requirements and existing test suites
Avoid shotgun debugging in favor of strategic investigation
Diff Patch Generation
Produce clean, minimal diffs that fix the issue without introducing regressions
Respect repository patterns and conventions
Ensure changes don't break existing functionality
Structured Problem Solving: Our Core Principles
Solving SWE Bench successfully requires more than just clever prompting—it demands a disciplined debugging methodology. We've distilled our approach into seven core principles that guide our agent's decision-making at every step:
1. Extract the Problem, Ignore Suggested Fixes
Focus on what's actually broken, not the user's proposed solution
Issue reporters often misdiagnose root causes or suggest suboptimal fixes
The agent must independently identify the real problem from symptoms described
2. Verify Actual Behavior, Don't Trust User Symptoms
Analyze the code execution path and logic flow
User descriptions may be incomplete, outdated, or inaccurate
Understand what the code actually does, not just what the issue claims
3. Fix Categories, Not Just Examples
Address the underlying class of bugs, not just the specific instance mentioned
If the issue shows one failing case, ensure all similar cases are handled
Think in terms of patterns and edge cases, not isolated fixes
4. Fix at Source/Origin, Not Downstream
Trace problems to their root cause
Avoid band-aid solutions that patch symptoms while leaving the real bug intact
A fix in the right place is simpler and more robust than multiple downstream patches
5. Preserve and Reuse Existing Code Patterns
Match the repository's idioms, conventions, and architectural patterns
Don't introduce novel approaches when the codebase has established patterns
Consistency matters for maintainability and reduces regression risk
6. Trace Complete Flow Before Fixing
Understand the full execution path from input to failure
Map out how data flows through the system and where it transforms
Premature fixes without complete understanding often miss edge cases
Our Step-by-Step Debugging Workflow
We guide our agent through a systematic eight-stage process that mirrors how experienced developers approach complex bugs:
1. Understand & Validate the Problem
Parse the issue description to extract the core problem
Separate symptoms from root causes
Identify what should happen vs. what actually happens
Clarify requirements and constraints
2. Explore & Hypothesize
Navigate the codebase using Potpie's knowledge graph
Identify relevant files, functions, and code paths
Form initial hypotheses about potential causes
Gather evidence to support or refute each hypothesis
3. Identify Root Cause
Trace the complete execution flow
Pinpoint where the actual problem originates
Distinguish between symptoms and the underlying issue
Verify understanding by analyzing code logic
4. Generalize the Issue
Expand from the specific example to the broader pattern
Identify all cases that could trigger the same bug
Consider edge cases and boundary conditions
Think like a repository maintainer: ensure the root cause is truly fixed, not just the symptom
Verify existing utility functions and classes that could be reused
Ensure the fix will handle the entire category of problems
5. Design Solution
Determine where the fix should be applied (origin, not downstream)
Choose an approach that aligns with existing code patterns
Reuse patterns already established in the codebase
Leverage existing utility functions and classes rather than reinventing solutions
Plan minimal, focused changes
Consider impact on related functionality
6. Scrutinize & Refine
Review the proposed solution against all requirements
Ensure changes are minimal and targeted—no unnecessary modifications
Maintain code quality and readability as a repository maintainer would
Check for potential regressions or side effects
Ensure consistency with repository conventions
Verify the solution keeps the codebase maintainable for future developers
Validate that all edge cases are covered
7. Implement
Generate clean, minimal diff patches
Maintain single-file changes where possible
Preserve existing code style and patterns
Apply the fix at the source of the problem
8. Final Verification
Confirm the solution addresses all requirements from the issue
Ensure the fix is complete and self-contained
Validate the patch is ready for evaluation
This systematic approach prevents the agent from jumping to premature solutions or missing critical requirements. Each stage builds on the previous one, creating a clear trail of reasoning that's both effective and debuggable. By thinking like a maintainer throughout the process, our agent produces patches that belong in the repository.
Enforcing the Methodology: Tools for Consistency
Having a clear debugging framework is one thing, getting an agent to actually follow it is another. LLMs are prone to shortcuts, skipping steps, or losing track of the bigger picture mid-execution. We solved this with two purpose-built tools that act as guardrails.
Todo Tool: Maintaining the Execution Plan
The todo tool keeps the agent on track throughout the debugging process:
Created during planning: When the agent formulates its approach, it generates a structured todo list capturing each step
Persistent task tracking: Todos remain visible across the agent's entire execution, preventing it from getting lost in details
Checkpoints after each task: After executing any action, the agent reviews the todo list to determine the next step
Prevents step-skipping: The agent can't jump from exploration directly to implementation—it must complete intermediate stages
Maintains focus: Even during long-running investigations, the agent stays oriented toward the larger plan
Requirements Tool: The Verification Checklist
The requirements tool was a game-changer for consistency:
Defined upfront: Agent creates a checklist of all requirements before starting execution
Dynamic updates: As the agent discovers new constraints or edge cases, it adds them to the requirements list
Strike irrelevant items: If initial assumptions prove wrong, the agent removes outdated requirements
Mandatory verification: Before proposing any solution, the agent must check every requirement
Pre-implementation gate: Agent validates all requirements are met before generating the final patch
Prevents partial solutions: Ensures the agent doesn't ship a fix that solves 80% of the problem
The Impact
These tools transformed our agent from inconsistent to reliable. The todo tool ensures systematic execution, while the requirements tool guarantees completeness. Together, they've helped us produce fairly consistent results across diverse SWE Bench instances.he agent no longer improvises its way through debugging.Without these tools, even the best prompting can't prevent an agent from drifting off course. The todo and requirements tools externalise the debugging plan and success criteria, making them concrete artifacts the agent must engage with throughout execution.
How Our Agent Interacts with the Codebase
To truly master a codebase, you have to do more than just read lines of code; you have to grasp the entire ecosystem of the repository. It’s about mapping how components interact, tracking the nuance of logic flow, and recognizing the deep patterns that hold a project together. By fusing traditional developer tools with Potpie’s graph-based intelligence, our agent navigates complex codebases with the speed and precision of a seasoned architect.
Foundation: Knowledge Graph Construction
Before the agent starts working, Potpie parses the entire repository and constructs extensive knowledge graphs. These graphs capture relationships between functions, classes, methods, imports, and other code entities. We build AI inference on top of these graph nodes, enabling semantic understanding beyond simple text matching.
Traditional Navigation Tools
The agent uses standard bash tools extensively:
grepfor pattern matching across filesfindfor locating files and directoriesblobfor content inspectioncatfor reading file contentsAnd many other unix utilities for file system navigation
These tools provide fast, precise access to specific code locations when the agent knows exactly what it's looking for.
Potpie-Specific Semantic Exploration: The Unfair Advantage
Traditional code navigation tools:grep, find, code search operate on a fundamental limitation: they see code as text. They can match patterns, find strings, and locate files, but they don't understand what the code does or how it fits into the larger system. For simple lookups, this is fine. For complex debugging? It's a serious handicap.
This is where Potpie's knowledge graph becomes a game-changer.
Beyond Text: Understanding Code Structure and Semantics

Potpie builds comprehensive knowledge graphs that represent your codebase across multiple hierarchies:
Structural nodes: Files, classes, functions, methods, variables
Behavioral nodes: API endpoints, database queries, event handlers
Architectural nodes: Modules, packages, dependency clusters
Relationship edges: Calls, imports, inheritance, data flow
But here's what makes it powerful: we run AI inference across these nodes in context. Each node isn't just a static label—it's enriched with deep insights about its functionality, its role in the system, and how it relates to surrounding code. The graph doesn't just know that function A calls function B; it understands why that relationship exists and what data flows between them.
Tools That Change Everything
1. AskKnowledgeGraphQueries: Semantic Code Search
Ask questions in natural language, get intelligent answers:
"Find all authentication middleware" → Not just grep for "auth", but actual middleware components based on their role
"Locate error handling patterns" → Discovers exception handling across the codebase, even with different naming conventions
"Where is user input validated?" → Traces data flow from entry points to validation logic
Why this matters for SWE Bench: When an issue mentions "authentication fails for special characters," you need to find not just files with "auth" in the name, but the actual validation logic, input sanitization functions, and edge case handlers. Semantic search finds these based on what they do, not what they're called.
2. GetProbableNodeID: Natural Language to Code Mapping
Describe what you're looking for; get the specific code entity:
"The function that parses SQL queries" → Points to the exact parser function
"Middleware that handles CORS" → Identifies the CORS handler even if it's named something obscure
"The class responsible for cache invalidation" → Finds it regardless of naming conventions
Why this matters for SWE Bench: Issue descriptions rarely use exact function names. They describe behavior: "the parser doesn't handle nested queries" or "caching breaks for concurrent requests." GetProbableNodeID bridges the gap between problem descriptions and actual code locations.
3. GetNodeNeighbours: Contextual Code Exploration
Understand code in its ecosystem:
What calls this function? → Find all invocation sites, understand usage patterns
What does it depend on? → Trace dependencies and shared state
What else uses this pattern? → Discover similar implementations that might have the same bug
Why this matters for SWE Bench: Bugs rarely exist in isolation. A validation issue in one function often appears in similar functions. GetNodeNeighbours helps you find all the places that need fixing, not just the obvious example from the issue.
The Compound Effect: Where Potpie Shines
Here's where the knowledge graph creates outsized value for SWE Bench:
Root Cause Analysis
Traditional: "This function throws an error" → grep for the function → read the code
Potpie: "This function throws an error" → GetNodeNeighbours to see what calls it → AskKnowledgeGraphQueries to find where the bad input originates → Trace the data flow through the graph → Identify the actual source of invalid data
Pattern Recognition
Traditional: Find one instance of the bug, fix it, hope there aren't more
Potpie: Find one instance → Ask "what else uses this pattern?" → Knowledge graph returns all similar code structures → Fix the entire category of bugs
Understanding Impact
Traditional: Make a fix, hope it doesn't break anything
Potpie: Before fixing → GetNodeNeighbours shows everything that depends on this code → AI inference explains what each dependent expects → Design fix that satisfies all constraints
Edge Case Discovery
Traditional: Read the issue, implement the obvious fix, miss edge cases
Potpie: Semantic exploration finds related validation logic → Knowledge graph reveals edge cases already handled elsewhere → Agent reuses proven patterns
The Real Difference
Without knowledge graphs, agents are like developers working in an unfamiliar codebase with only grep and intuition. They can eventually figure things out, but it's slow and error-prone.
With Potpie's knowledge graphs, agents have something closer to a senior developer's mental model of the codebase: understanding not just where code is, but what it does, why it exists, and how it fits together.
This isn't a marginal improvement—it's the difference between stumbling through a dark room and having a map with annotations. For SWE Bench, where understanding complex, unfamiliar codebases quickly is critical, this is the foundation that makes systematic, reliable debugging possible.
Traditional tools answer "where is this string?" Potpie's knowledge graph answers "how does this system work?" That's not just a better tool—it's a fundamentally different capability. And for solving real-world bugs in production codebases, that difference is everything.
Keeping It Clean
Raw retrieval from large repositories would quickly overwhelm the context window. We've built several safeguards:
File Size Limits
Many repositories contain huge files (thousands of lines)
The agent can limit retrieval by file size
For large files, fetch only relevant portions rather than everything
CodeAnalysis Tool
Indexes files into key nodes: functions, classes, methods, and their signatures
Allows the agent to "peek" at a file's structure without reading all implementation details
Enables targeted retrieval of specific, possibly relevant code snippets
Agent sees what's available before deciding what to fetch in full
Selective Node Retrieval
Knowledge graph tools fetch individual nodes, not entire files
Agent can pull just the relevant function or class instead of 500 lines of unrelated code
Dramatically reduces noise in the context window
Keeps the LLM focused on what actually matters for the current task
This multi-layered approach—bash tools for precision, knowledge graphs for semantic exploration, and targeted retrieval for context management—gives our agent the ability to navigate unfamiliar codebases efficiently while maintaining the clean, focused context essential for reasoning about complex bugs.
The C Word: Context
Context management is the ultimate bridge between a good agent and a truly exceptional one. It is the core engine of reliability, the defining factor that enables an agent to solve problems systematically rather than losing its way during execution.
Why Context Management Is Critical
Hard problems require many iterations and extended execution time. An agent might spend thousands of tokens exploring the codebase, forming hypotheses, analyzing code paths, and validating solutions. Throughout this entire journey, the agent must:
Stay on track: Remember the original problem, the current debugging stage, and the overall plan
Have relevant information at every phase: The right code snippets, the right requirements, the right context for the current task
Maintain focus: Avoid drowning in irrelevant details while ensuring no critical information is missed
The Triple Benefit of Concise Context
Keeping context lean and targeted delivers three major advantages:
Easier Problem Solving
The task becomes clear when the agent sees exactly what matters
No wading through pages of irrelevant code to find the one crucial function
Relevant instructions and information are immediately accessible
Faster Execution
Smaller LLM calls mean faster response times
Agent spends less time processing noise, more time reasoning about the problem
Quicker iteration cycles lead to faster time-to-solution
Lower Costs
Token usage directly impacts cost
A 10,000-token context vs. a 50,000-token context adds up quickly across hundreds of instances
Efficient context management makes experimentation and scaling economically viable
Potpie's Multi-Agent Setup: Strategic Context Management
Potpie's core strength is its knowledge graph and inference system. They together provides valuable insights into code snippets and the broader codebase. This helps agents explore faster, find relevant code, identify patterns and usage, and surface key insights like inconsistencies and bugs. These capabilities empower the agent to make more accurate decisions, faster and more reliably, at every step.
But knowledge graphs alone don't solve the context problem. For long-running SWE Bench tasks, we need intelligent architecture to keep context clean and effective.
The Architecture: Supervisor and Subagents
Potpie uses a multi-agent setup consisting of:
Supervisor Agent: The orchestrator that maintains the overall debugging strategy, tracks progress, and makes high-level decisions
Think-and-Execute Subagent: Handles arbitrary tasks delegated by the supervisor
Integration Subagents: Specialized agents for GitHub, Jira, and other external services
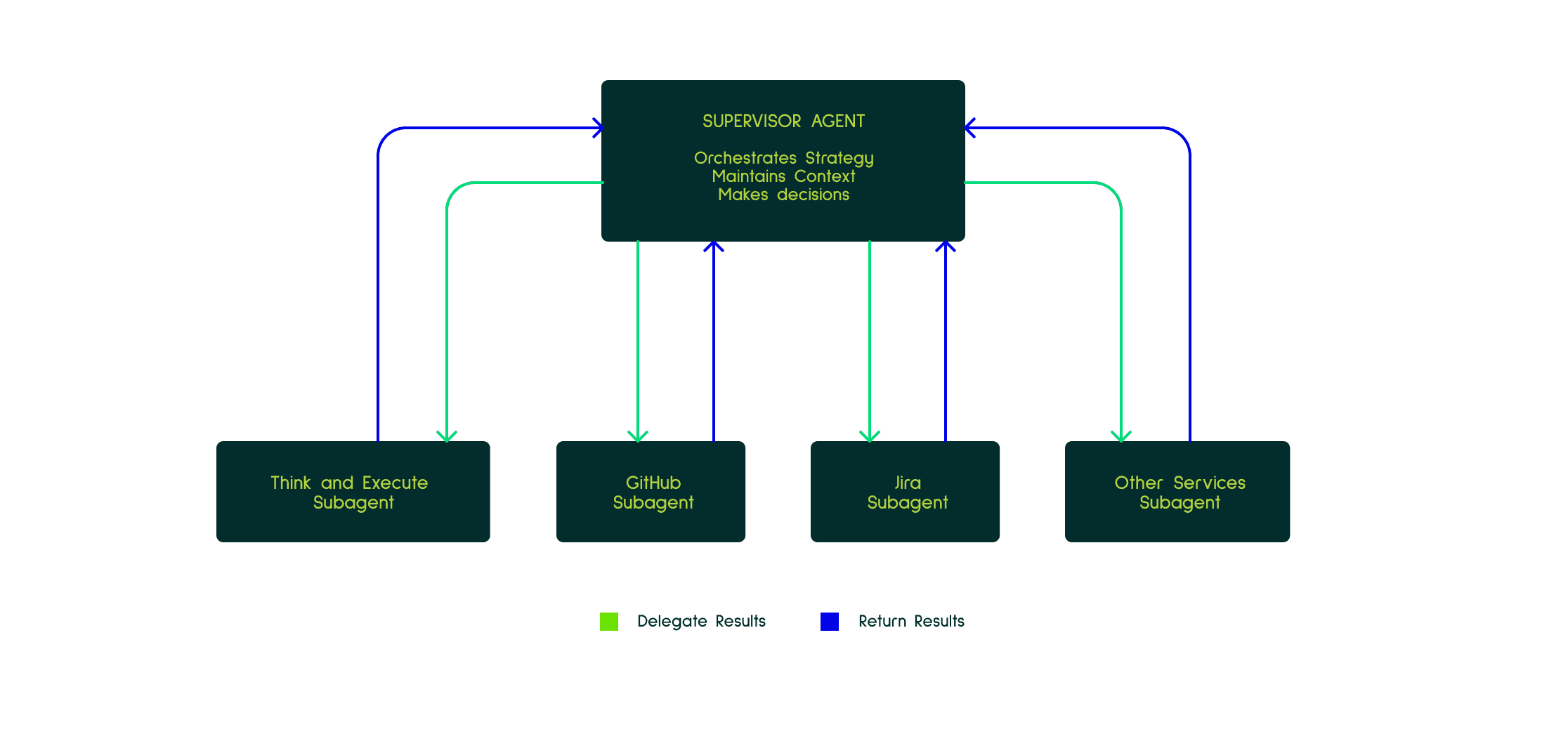
Important: We deliberately don't use specialized subagents like "context gatherers" or "verifiers." The supervisor maintains its own context and makes its own verification decisions.
Why This Architecture? Context Streamlining
The primary purpose of this design is to keep the supervisor's context lean and strategically organized.
What the Supervisor Maintains:
Flow of its reasoning across the debugging process
Key insights discovered during exploration
Concise summary of what approaches were tried
Current progress and next steps
Relevant code snippets and codebase context
Why the Supervisor Keeps Code Context:
We experimented with delegating context gathering to subagents but found that gathered context is crucial for supervisor decision-making. Yes, this context can get messy during retrieval, but the solution isn't to push it all out of the main context—it's to manage relevant context better at the supervisor level. The supervisor needs to see code to make informed decisions about where to explore next, which hypotheses to pursue, and whether a solution is correct.
The Four Key Benefits
1. Clean Supervisor Context Through Strategic Delegation
When the supervisor delegates a task to a subagent, all the fine-grained details—tool calls, intermediate reasoning steps, failed attempts—stay in the subagent's context. The supervisor receives only the concise result of the task, which is what it actually needs to continue.
For example:
Supervisor: "Fetch the implementation of the
parse_queryfunction"Subagent: [navigates file system, tries multiple searches, handles errors, fetches code]
Supervisor receives: Just the function implementation
The supervisor's context doesn't contain the 15 tool calls the subagent made—just the outcome.
2. Tool Grouping and Abstraction
With too many tools and prompts, LLMs struggle to choose the right action. Subagents solve this by logically grouping tools:
Rarely-used tools (GitHub API calls, Jira updates) live in specialized subagents
The supervisor's tool list stays focused on core debugging operations
LLMs make better decisions when they're not overwhelmed with 50+ tool options
3. Parallelization
Multiple subagents can work simultaneously on independent tasks:
One subagent fetches code from multiple files
Another analyzes test cases
A third explores related issues
This speeds up execution significantly compared to sequential processing.
4. Clean Process History
The supervisor maintains a clear narrative of the debugging journey:
"Explored authentication flow → Found mismatch in validation logic → Verified pattern in similar code → Designed fix → Implemented patch"
Not:
"Called grep 47 times, fetched 12 files, ran code analysis on 8 functions, tried 3 different search patterns..."
The supervisor sees the forest, not every individual tree.
Strategic Delegation is Key
This architecture only works if the supervisor delegates thoughtfully:
✅ Delegate: "Fetch all test files related to authentication"
❌ Don't delegate: "Should we explore the auth module or the validation module next?" (This is a decision the supervisor needs to make)
The supervisor must retain enough context to reason about the problem while offloading mechanical execution to subagents.
Managing Context Over Time: The History Processor
Even with strategic subagent delegation, long-running debugging sessions accumulate context. An agent exploring dozens of files, testing multiple hypotheses, and iterating through solutions can easily hit context limits. Potpie's solution: a custom history processor that actively manages the message history throughout the agent run.
How It Works
The history processor monitors and maintains context dynamically:
Threshold-based activation: Kicks in when context usage reaches around 40-45%
Aggressive trimming: Removes older tool call results from the message history
Re-callable information: If the agent needs previously trimmed information, it simply calls the tool again
Continuous management: Keeps context usage around the 40-45% range throughout the entire run
Applies to all agents: Both supervisor and subagents benefit from this context management
The Trade-offs
This approach has clear trade-offs:
Potential slowdown: If the agent needs previously retrieved information, it must fetch it again, adding latency
Increased reliability: Agents solve one task at a time with only the relevant information in current context
In practice, we've found the benefits far outweigh the occasional redundant fetch.
The Benefits
1. Focused Attention
Agent works with what's relevant now, not everything it's seen across the entire run
Reduces noise and cognitive load on the LLM
Clearer task context leads to better decision-making
2. Consistent Token Usage
No exponential context growth as the agent runs longer
Token consumption stays predictable and manageable
Makes it economically feasible to let agents run for extended periods
3. Reliable Long-Running Tasks
Agents don't hit context limits mid-execution
Can sustain deep investigation without degradation
Tougher problems that require extended exploration remain solvable
4. Natural Problem-Solving Pace
Harder problems naturally take more time to solve
The agent isn't artificially constrained by context limits
Mirrors how human developers work: complex bugs require more investigation
The Philosophy
This design embodies a key principle: tougher problems should require longer time to solve, and that's okay.
We're not optimizing for the fastest possible completion on easy instances. We're building an agent that can handle the hard cases—the bugs that require exploring multiple hypotheses, tracing complex execution flows, and verifying edge cases across the codebase.
The history processor enables this by ensuring the agent can run as long as needed without context degradation. It's the difference between an agent that gives up after 20 minutes because its context is polluted versus one that methodically works through a difficult problem for an hour and produces a correct solution.
Combined with our multi-agent architecture, the history processor creates a system that stays clean, focused, and effective throughout long debugging sessions. Context management isn't an afterthought—it's a core design principle that makes extended, systematic problem-solving possible.
Putting It All Together: Building Agents That Actually Work
Solving SWE Bench isn't about finding a magic prompt or throwing more compute at the problem. It's about building a complete system that addresses the fundamental challenges of automated debugging: understanding complex codebases, maintaining context over long runs, following systematic processes, and making decisions like an experienced developer.
Our approach with Potpie brings together multiple innovations:
Knowledge graphs that provide semantic understanding of codebases, not just text matching
Custom agents tailored specifically for debugging workflows with targeted tools and instructions
Structured methodology enforced through todo and requirements tools that prevent shortcuts
Multi-agent architecture that keeps context clean through strategic delegation
Active context management via history processing that enables extended problem-solving sessions
Principled debugging that fixes root causes, reuses patterns, and thinks like a repository maintainer
None of these pieces alone would be sufficient. It's the combination—the systematic approach, the semantic code understanding, the disciplined context management—that enables our agent to tackle real-world bugs effectively.
What's Next
SWE Bench remains a challenging benchmark, and we're continuously iterating on our approach. Every failed instance teaches us something about where our methodology breaks down, where our knowledge graphs need richer inference, or where our context management could be smarter.
We're building in the open because we believe the future of software development involves AI agents that truly understand code—not as sequences of tokens, but as systems with structure, semantics, and purpose. Potpie's knowledge graph foundation is core to that vision.
Try It Yourself
Potpie is open source and available now. Whether you're tackling SWE Bench, building your own coding agents, or just exploring what's possible with AI-powered development tools, we'd love to have you try us out.
Check out Potpie at potpie.ai and see how knowledge graphs can transform the way AI agents understand and work with code.
" height="176.48689063250688px" id="t2zO9Quc7" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="1.55" stroke="rgb(180, 209, 63)" transform="translate(0.773 0.758)" width="307.0499654602649px"/></svg>)
" height="127.83155915492955px" id="F7uNl9dyd" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(8.021 100.549)" width="136.10429429577454px"/><path d="M 120.738 0 L 166.541 2.512 L 302.646 81.116 L 259.995 105.741 L 140.463 174.742 L 48.783 121.822 L 39.844 116.65 L 21.917 106.308 L 4.359 96.162 L 0 69.714 Z M 84.883 90.646 L 93.847 95.818 L 111.75 106.16 L 140.734 122.881 L 155.534 97.468 L 158.883 91.73 L 212.812 81.264 L 161.197 51.467 L 141.177 39.918 L 130.096 46.32 L 124.653 49.473 L 69.099 81.535 Z M 27.753 84.712 L 130.096 25.635 L 146.718 16.031 L 130.096 15.292 L 26.472 75.132 Z" fill="rgb(0, 53, 51)" height="174.74215475179432px" id="XL4eRTHOZ" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(3.647 4.386)" width="302.6461113816823px"/><path d="M 0 0 L 0 10.343 L 16.622 0.739 Z" fill="rgb(0, 53, 51)" height="10.34275225352113px" id="cBwRaCSIs" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(133.76 19.669)" width="16.622023943661958px"/><path d="M 0 59.84 L 1.28 69.419 L 103.623 10.343 L 103.623 0 Z" fill="rgb(0, 53, 51)" height="69.41898253521126px" id="yI1DYW3PI" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(30.132 19.669)" width="103.62314999999992px"/><path d="M 0 0 L 0 49.251 L 14.357 57.55 L 17.706 51.812 L 71.636 41.346 L 20.021 11.549 Z" fill="rgb(0, 53, 51)" height="57.54972676056339px" id="swIgz6ZQs" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(144.827 44.294)" width="71.63555704225351px"/><path d="M 0 41.617 L 15.785 50.728 L 24.748 55.9 L 42.651 66.242 L 72.078 49.251 L 72.078 0 L 60.997 6.403 L 55.555 9.555 Z" fill="rgb(0, 53, 51)" height="66.2424190140845px" id="Ou0foMTnv" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(72.761 44.294)" width="72.07816690140838px"/><path d="M 0 93.626 L 0 142.877 L 162.183 49.251 L 162.183 0 L 119.532 24.626 Z" fill="rgb(0, 53, 51)" height="142.87681267605637px" id="F6Glizjhy" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(144.11 85.495)" width="162.1830021126761px"/><path d="M 0 0 L 0 49.251 L 4.359 75.699 L 4.359 26.448 Z" fill="rgb(0, 53, 51)" height="75.69868943661974px" id="CEJbzDHVA" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(3.661 74.105)" width="4.358684366197165px"/></svg>)
" height="275.2348071827544px" id="tOCVqXAMo" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.05" stroke="rgb(180, 209, 63)" transform="translate(2.023 1.876)" width="306.08189403973506px"/></svg>)
" height="272.22086421478906px" id="PPsuL8gM9" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.04" stroke="rgb(180, 209, 63)" transform="translate(2.016 1.798)" width="306.4324539473682px"/></svg>)
" height="176.48689063250686px" id="YZ_qP17EP" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="1.55" stroke="rgb(180, 209, 63)" transform="translate(0.773 0.758)" width="307.04996546026496px"/><g d="M 62.549 28.787 C 62.536 28.761 62.526 28.736 62.519 28.709 C 62.535 28.768 62.56 28.824 62.6 28.878 C 62.578 28.849 62.562 28.818 62.549 28.787 Z M 62.549 28.787 L 62.6 28.878 C 62.56 28.824 62.535 28.768 62.519 28.709 Z M 54.656 27.136 L 53.678 29.273 C 52.829 31.129 53.725 33.105 56.041 34.482 L 67.491 41.285 L 70.928 43.27 C 73.406 44.7 77.049 45.237 80.421 44.654 L 121.141 37.611 C 120.159 39.696 120.291 41.929 121.582 44.003 C 125.001 49.499 120.112 55.555 110.627 57.574 C 105.569 58.649 101.585 60.95 99.722 63.869 C 96.226 69.347 85.734 72.169 76.215 70.194 C 71.142 69.142 65.525 69.424 60.847 70.967 C 52.07 73.864 40.885 72.132 35.787 67.087 C 33.07 64.398 28.45 62.529 23.146 61.975 C 13.195 60.934 6.552 55.458 8.262 49.704 C 9.172 46.637 7.711 43.493 4.263 41.1 C -2.205 36.611 -1.202 29.951 6.515 26.18 C 10.627 24.17 13.008 21.221 13.03 18.11 C 13.07 12.271 21.254 7.547 31.367 7.524 C 36.757 7.511 41.866 6.135 45.347 3.761 C 50.795 0.044 59.728 -0.975 67.055 0.959 Z M 121.101 29.063 C 121.295 29.225 121.319 29.421 121.365 29.811 C 121.437 30.422 121.416 31.043 121.303 31.658 C 121.245 31.973 121.216 32.132 121.07 32.303 C 120.952 32.442 120.731 32.596 120.516 32.689 C 120.25 32.804 119.941 32.858 119.324 32.965 L 78.041 40.112 C 77.569 40.193 77.056 40.118 76.707 39.917 L 73.268 37.93 C 72.552 37.516 72.859 36.812 73.828 36.645 L 118.972 28.911 C 119.692 28.787 120.052 28.726 120.384 28.774 C 120.655 28.814 120.941 28.93 121.101 29.063 Z M 77.422 5.057 L 85.829 15.345 L 85.834 15.352 C 85.944 15.485 85.999 15.553 86.076 15.611 C 86.144 15.664 86.226 15.711 86.317 15.751 C 86.42 15.796 86.54 15.83 86.779 15.895 L 107.021 21.407 L 107.041 21.413 C 107.775 21.613 108.144 21.713 108.236 21.838 C 108.316 21.947 108.297 22.073 108.187 22.173 C 108.059 22.288 107.655 22.352 106.863 22.48 L 64.254 29.318 C 63.803 29.4 63.362 29.338 63.037 29.193 L 62.989 29.169 C 62.826 29.09 62.694 28.987 62.61 28.87 L 62.559 28.779 L 62.529 28.701 C 62.501 28.597 62.509 28.489 62.561 28.376 L 73.706 5.239 L 73.713 5.226 C 74.151 4.315 74.371 3.857 74.769 3.71 C 75.115 3.582 75.548 3.562 75.927 3.654 C 76.364 3.761 76.717 4.193 77.422 5.057 Z" fill="transparent" height="72.36999344346039px" id="PThBnjLXo" transform="translate(95.525 49.205)" width="122.67217843649964px"><path d="M 0.03 0.077 C 0.017 0.052 0.007 0.027 0 0 C 0.016 0.059 0.041 0.115 0.081 0.169 C 0.059 0.139 0.043 0.109 0.03 0.077 Z" fill="rgb(180, 209, 63)" height="1px" id="FZhYXbO6L" transform="translate(62.519 28.709)" width="1px"/><path d="M 62.549 28.787 L 62.6 28.878 C 62.56 28.824 62.535 28.768 62.519 28.709 Z M 54.656 27.136 L 53.678 29.273 C 52.829 31.129 53.725 33.105 56.041 34.482 L 67.491 41.285 L 70.928 43.27 C 73.406 44.7 77.049 45.237 80.421 44.654 L 121.141 37.611 C 120.159 39.696 120.291 41.929 121.582 44.003 C 125.001 49.499 120.112 55.555 110.627 57.574 C 105.569 58.649 101.585 60.95 99.722 63.869 C 96.226 69.347 85.734 72.169 76.215 70.194 C 71.142 69.142 65.525 69.424 60.847 70.967 C 52.07 73.864 40.885 72.132 35.787 67.087 C 33.07 64.398 28.45 62.529 23.146 61.975 C 13.195 60.934 6.552 55.458 8.262 49.704 C 9.172 46.637 7.711 43.493 4.263 41.1 C -2.205 36.611 -1.202 29.951 6.515 26.18 C 10.627 24.17 13.008 21.221 13.03 18.11 C 13.07 12.271 21.254 7.547 31.367 7.524 C 36.757 7.511 41.866 6.135 45.347 3.761 C 50.795 0.044 59.728 -0.975 67.055 0.959 Z M 121.101 29.063 C 121.295 29.225 121.319 29.421 121.365 29.811 C 121.437 30.422 121.416 31.043 121.303 31.658 C 121.245 31.973 121.216 32.132 121.07 32.303 C 120.952 32.442 120.731 32.596 120.516 32.689 C 120.25 32.804 119.941 32.858 119.324 32.965 L 78.041 40.112 C 77.569 40.193 77.056 40.118 76.707 39.917 L 73.268 37.93 C 72.552 37.516 72.859 36.812 73.828 36.645 L 118.972 28.911 C 119.692 28.787 120.052 28.726 120.384 28.774 C 120.655 28.814 120.941 28.93 121.101 29.063 Z M 77.422 5.057 L 85.829 15.345 L 85.834 15.352 C 85.944 15.485 85.999 15.553 86.076 15.611 C 86.144 15.664 86.226 15.711 86.317 15.751 C 86.42 15.796 86.54 15.83 86.779 15.895 L 107.021 21.407 L 107.041 21.413 C 107.775 21.613 108.144 21.713 108.236 21.838 C 108.316 21.947 108.297 22.073 108.187 22.173 C 108.059 22.288 107.655 22.352 106.863 22.48 L 64.254 29.318 C 63.803 29.4 63.362 29.338 63.037 29.193 L 62.989 29.169 C 62.826 29.09 62.694 28.987 62.61 28.87 L 62.559 28.779 L 62.529 28.701 C 62.501 28.597 62.509 28.489 62.561 28.376 L 73.706 5.239 L 73.713 5.226 C 74.151 4.315 74.371 3.857 74.769 3.71 C 75.115 3.582 75.548 3.562 75.927 3.654 C 76.364 3.761 76.717 4.193 77.422 5.057 Z" fill="rgb(180, 209, 63)" height="72.36999344346039px" id="AQyCIziS7" transform="translate(0 0)" width="122.67217843649964px"/></g></svg>)
" height="150.90560294117645px" id="jxii70vzV" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(24.37 4.791)" width="261.37546588235216px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.728 3.018 L 116.384 4.988 L 123.793 7.455 L 130.373 10.224 L 136.629 13.481 L 142.286 17.103 L 147.097 20.91 L 151.356 25.179 L 154.784 29.643 L 157.336 34.117 L 159.104 38.936 L 159.995 43.657 L 159.981 48.672 L 159.104 53.438 L 157.336 58.222 L 154.784 62.73 L 151.356 67.194 L 147.128 71.41 L 142.286 75.271 L 136.629 78.892 L 130.373 82.149 L 123.686 84.945 L 116.384 87.386 L 108.728 89.356 L 100.843 90.838 L 92.557 91.859 L 84.164 92.374 L 75.632 92.365 L 67.439 91.859 L 59.322 90.865 L 51.344 89.365 L 43.611 87.386 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.464 L 8.639 67.194 L 5.227 62.775 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.782 L 0.892 38.936 L 2.613 34.25 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.37355058823529px" id="LN6Mj2wjX" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.05 69.207)" width="159.99511058823543px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.729 3.018 L 116.383 4.988 L 123.794 7.455 L 130.374 10.224 L 136.63 13.481 L 142.287 17.103 L 147.098 20.91 L 151.357 25.179 L 154.785 29.643 L 157.337 34.117 L 159.103 38.936 L 159.996 43.657 L 159.979 48.672 L 159.103 53.438 L 157.337 58.222 L 154.785 62.73 L 151.357 67.194 L 147.129 71.41 L 142.287 75.271 L 136.63 78.892 L 130.374 82.149 L 123.687 84.946 L 116.383 87.385 L 108.729 89.355 L 100.843 90.838 L 92.557 91.858 L 84.164 92.374 L 75.632 92.365 L 67.439 91.858 L 59.322 90.864 L 51.344 89.364 L 43.611 87.385 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.463 L 8.639 67.194 L 5.227 62.775 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.781 L 0.892 38.936 L 2.613 34.25 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.37427764705882px" id="jDPtsCydt" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.76 83.833)" width="159.99583764705716px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.728 3.018 L 116.384 4.988 L 123.793 7.455 L 130.373 10.224 L 136.629 13.481 L 142.286 17.103 L 147.097 20.91 L 151.356 25.179 L 154.784 29.643 L 157.336 34.117 L 159.104 38.936 L 159.995 43.657 L 159.981 48.672 L 159.104 53.438 L 157.336 58.222 L 154.784 62.73 L 151.356 67.194 L 147.128 71.41 L 142.286 75.271 L 136.629 78.892 L 130.373 82.149 L 123.686 84.945 L 116.384 87.386 L 108.728 89.356 L 100.843 90.838 L 92.557 91.859 L 84.164 92.374 L 75.632 92.365 L 67.439 91.859 L 59.322 90.865 L 51.344 89.365 L 43.611 87.386 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.464 L 8.639 67.194 L 5.227 62.775 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.782 L 0.892 38.936 L 2.613 34.25 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.37355058823529px" id="UKafYhxUp" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.05 69.207)" width="159.99511058823543px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.728 3.018 L 116.384 4.988 L 123.793 7.455 L 130.373 10.224 L 136.629 13.481 L 142.286 17.103 L 147.097 20.91 L 151.356 25.179 L 154.784 29.643 L 157.336 34.117 L 159.104 38.936 L 159.995 43.657 L 159.981 48.672 L 159.104 53.438 L 157.336 58.222 L 154.784 62.73 L 151.356 67.194 L 147.128 71.41 L 142.286 75.271 L 136.629 78.892 L 130.373 82.149 L 123.686 84.945 L 116.384 87.386 L 108.728 89.356 L 100.843 90.838 L 92.557 91.859 L 84.164 92.373 L 75.632 92.365 L 67.439 91.859 L 59.322 90.865 L 51.344 89.365 L 43.611 87.386 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.463 L 8.639 67.194 L 5.227 62.775 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.781 L 0.892 38.936 L 2.613 34.25 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.3733688235294px" id="BTS7eFR5p" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.05 48.404)" width="159.99511058823543px"/><path d="M 128.886 85.255 L 0 105.189 L 0 19.934 L 128.886 0 Z" fill="transparent" height="105.18923470588237px" id="XpYvdAzW3" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(57.724 4.311)" width="128.88608117646865px"/><path d="M 92.835 53.589 L 92.835 138.028 L 0 84.439 L 0 0 Z" fill="transparent" height="138.02757352941174px" id="K8lS4_UO3" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(192.202 5.927)" width="92.8345058823547px"/><path d="M 30.371 77.481 L 0 142.926 L 0 65.41 L 30.371 0 Z" fill="transparent" height="142.92631411764705px" id="ckGqTr2MB" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(21.656 34.705)" width="30.37088294117827px"/><path d="M 30.371 77.481 L 0 142.928 L 0 65.411 L 30.371 0 Z" fill="transparent" height="142.9275864705882px" id="r3233RfUB" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(254.683 70.769)" width="30.371064705883697px"/><path d="M 92.835 53.589 L 92.835 138.027 L 0 84.439 L 0 0 Z" fill="transparent" height="138.02721000000003px" id="LSrhVSYKp" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(21.656 104.548)" width="92.83486941176557px"/><path d="M 128.886 85.255 L 0 105.19 L 0 19.934 L 128.886 0 Z" fill="transparent" height="105.18959823529411px" id="x2Xopuli2" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(120.064 138.931)" width="128.88626294117825px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.728 3.017 L 116.384 4.988 L 123.793 7.455 L 130.373 10.224 L 136.629 13.481 L 142.286 17.103 L 147.097 20.91 L 151.356 25.179 L 154.784 29.643 L 157.336 34.116 L 159.104 38.936 L 159.995 43.657 L 159.981 48.672 L 159.104 53.438 L 157.336 58.221 L 154.784 62.73 L 151.356 67.194 L 147.128 71.41 L 142.286 75.271 L 136.629 78.892 L 130.373 82.149 L 123.686 84.945 L 116.384 87.385 L 108.728 89.356 L 100.843 90.838 L 92.557 91.859 L 84.164 92.373 L 75.632 92.364 L 67.439 91.859 L 59.322 90.865 L 51.344 89.365 L 43.611 87.385 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.463 L 8.639 67.194 L 5.227 62.774 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.781 L 0.892 38.936 L 2.613 34.249 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.3733688235294px" id="dtqTIoHPq" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.05 30.156)" width="159.99511058823543px"/></svg>)
" width="309px"><path d="M 0 0 C 62.424 52.356 97.323 76.699 124.122 133.612 C 125.774 137.121 129.275 139.414 133.153 139.414 L 178.332 139.414 C 182.27 139.414 185.824 137.027 187.434 133.433 C 220.347 59.939 255.786 56.508 309 0 C 223.902 11.24 92.218 13.79 0 0 Z" fill="rgb(244, 255, 200)" height="139.41414141414143px" id="YPPdTHgjp" width="309px"/></g></svg>)
" width="291.547144895145px"><path d="M 2.159 40.336 L 81.816 193.109 C 85.087 199.382 91.575 203.316 98.649 203.316 L 199.157 203.316 C 206.445 203.316 213.09 199.143 216.257 192.578 L 289.654 40.384 C 294.95 29.401 288.66 16.33 276.702 13.944 C 186.518 -4.05 102.962 -5.096 14.535 13.537 C 2.503 16.072 -3.526 29.434 2.159 40.336 Z" fill="rgb(174, 218, 0)" height="203.31595618278868px" id="beF0XCFO6" transform="translate(0 0)" width="291.54714489452647px"/></g></svg>)
" width="279.949712674067px"><path d="M 1.851 35.23 L 64.467 192.416 C 68.34 202.139 77.749 208.518 88.214 208.518 L 194.612 208.518 C 205.187 208.518 214.67 202.007 218.469 192.138 L 278.208 36.927 C 285.378 18.296 269.348 -1.055 249.578 1.717 C 168.185 13.131 109.4 10.303 29.167 0.211 C 9.712 -2.236 -5.406 17.013 1.851 35.23 Z" fill="rgb(145, 181, 0)" height="208.51809526570761px" id="tGoxWLGVd" transform="translate(0 0)" width="279.94971259877605px"/></g></svg>)
Recommended Blogs






























