


The quality of an AI harness is determined almost entirely by the quality of context it has access to. Without the right context, even the most sophisticated model will produce answers that are technically correct but practically useless. With the right context, even simpler models can give you something genuinely actionable.
Most AI coding tools sell on the same promise: connect your repository and start immediately. For smaller projects with straightforward architectures, this actually works. The first 20% of context gets you 80% of the value. Sometimes, a quick repo connection and surface-level parsing is genuinely enough to get useful answers. But as codebase complexity grows with more services, legacy code, undocumented dependencies, this approach plateaus quickly. The gap between "surface context" and "deep context" widens, and what worked for a startup becomes a liability for an enterprise.
This is where the sales pitch starts to diverge from reality. Walk a standard AI tool demo into a real enterprise engineering org and something different happens. The outputs feel generic. The agent misses context that's obvious to anyone on the team. The performance difference for smaller, medium complexity repos and enterprise repos become really evident. This gap is more subtle and more common than people admit. Enterprise environments have implicit constraints, undocumented conventions, and layers of operational history that don't surface in obvious errors. Instead, you get silent failures where the agent produces answers that look right but miss critical context, or suggests solutions that ignore how your team actually works. The tool works fine, it's just working on incomplete information, and the cost shows up slowly in accumulated friction and declining trust.
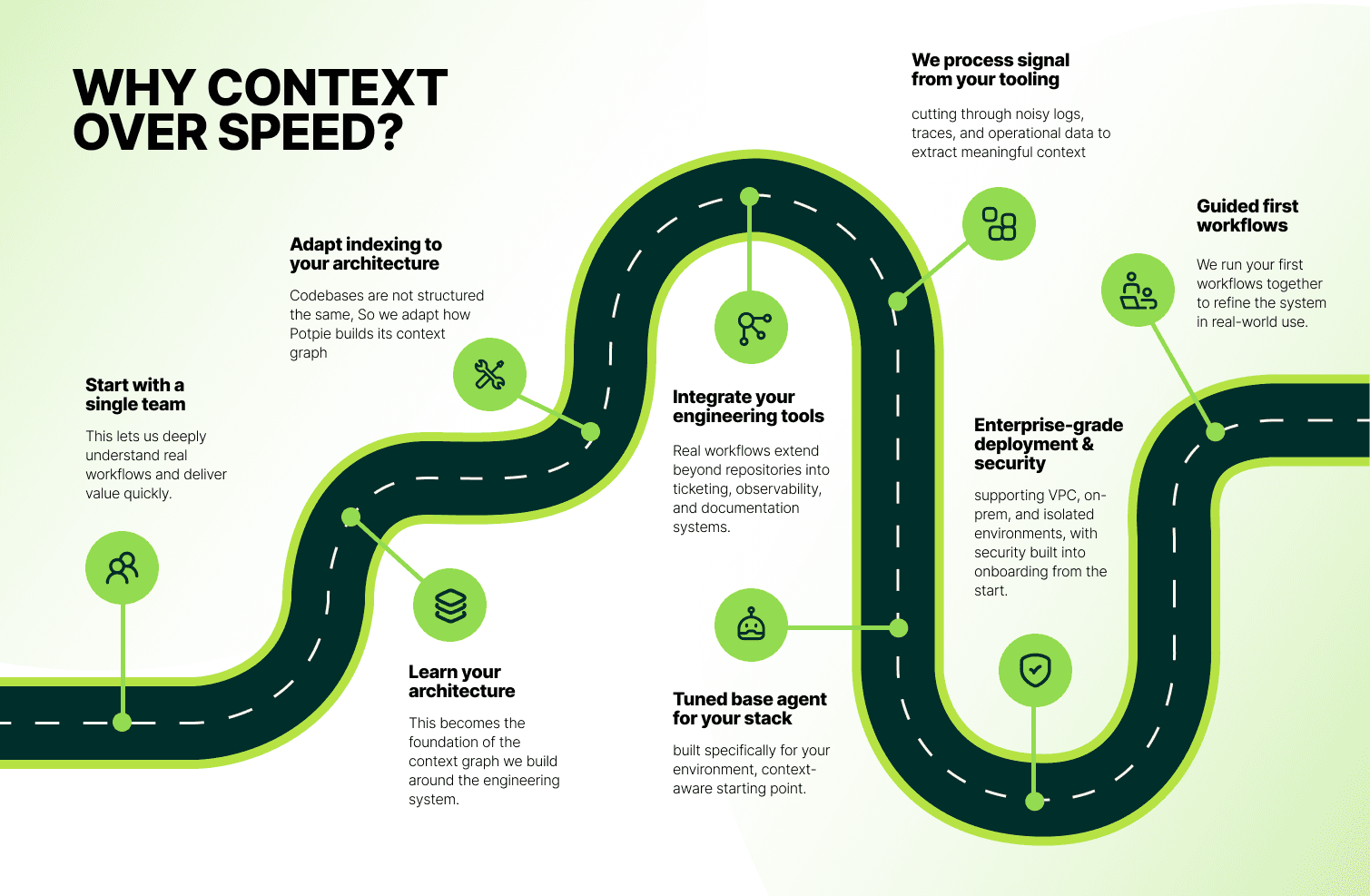
This gap between demo and reality doesn't get talked about enough, and it leads to frustration, wasted investment, and tools being thrown out before they've really been given a chance. Understanding what it actually takes to make an AI tool useful in a complex environment changes how you evaluate options. So here's exactly how Potpie onboards every team, step by step, to make sure their agent coding workflow is contextual and consistent from day zero, not six months in after a lot of trial and error.
1. Start with one team
Not one department. One team. One specific workflow.
Rolling out across an entire organization on day one sounds very lucrative. But in practice, it spreads the engineering resources so thin that nothing works well for anyone. You end up with people who have tried it, everyone shrugging, and no clear signal about what needs fixing. Working with one team allows you navigating through the depth of the problem and identifying what works right for this particular stack.
2. Spend real time mapping the architecture
Enterprise codebases are messy and carry years of decisions made by people who have since left the company, using languages and frameworks chosen for reasons nobody fully remembers. Services call other services in ways that aren't documented anywhere except in someone's head. Before Potpie can work with any of this, we need to understand how it's actually wired. Not how it's supposed to be wired. Not what the architecture diagram from 2019 says. How it works today. That mapping becomes the foundation of the context we build. Without it, every answer the agent gives is just a guess. Customizing how that context gets collected, prioritizing the right services, understanding internal naming conventions, mapping actual call patterns rather than declared dependencies makes the difference between an agent that sounds right and one that actually helps.
3. Customize how context gets indexed
Generic indexing and tool strategies assume standard project layouts. That assumption fails for monorepos with 40+ services, micro-frontends, or domain layers that don't follow convention. We configure how the agent traverses your codebase: which files to prioritize, how to weight cross-service dependencies, which naming conventions matter, and how to resolve references that don't match the directory structure.
4. Bring in the full toolchain
The repository is not the whole story. Not even close. Real engineering work touches Jira, Datadog, Confluence, internal deployment systems, and custom tools your team has built up over the years. An agent that only sees the code is missing the context that makes any of it make sense. When we pull in the toolchain, the answers start sounding less generic and more like a senior engineer who knows the full picture.
5. Pull signals from your operational data
Logs, traces, alerts, and incident notes contain the real history of your system. They're also unstructured, noisy, and stored across multiple systems.
Most agents skip this entirely because ingestion is non-trivial. We clean, parse, and index operational data so the agent can reference it during incidents, debugging sessions, and postmortems. This evolves the tool from just writing code to debugging issues in production.
6. Tune retrieval for your specific stack
Different tech stacks need different context strategies. A Spring Boot monolith and a Kubernetes-based micro services architecture don't benefit from the same retrieval patterns. We configure which context sources the agent queries, how it weights recency versus relevance, and which tools it has access to for each type of question. This upfront work means engineers don't spend time adding extra information on top of every prompt compared to a non-context aware harness.
7. Build security constraints from day one
Enterprise deployment has real blockers: air-gapped networks, SOC 2 requirements, data residency rules, strict RBAC. Tools that treat these as afterthoughts never make it past the security review. We map your compliance requirements even before integration starts. This prevents any legal limbo during deployment and integration.
8. We train your engineers on how to use it
Most engineers haven't worked with context-aware agents before. Without guidance, they treat it like ChatGPT, ask generic questions, get generic answers, and stop using it.
We show them how the context layer works, what information the agent has access to, and how to structure questions that leverage that context. Once they understand the model, they start using it in ways that weren't obvious from the start.
Once they understand how the agent thinks, they start asking better questions. They give it more context and the right context. As the trust builds up, engineers start to experiment with new workflows for their development, and that is where you start to see productivity gains.
Single-click onboarding assumes the environment is already simple. Enterprise environments almost never are.
This changes how you evaluate AI tools. Not "can I connect it in five minutes?" but "what does it take to make this useful in our system?"
That's the question we're built around. More upfront effort. The only approach that works when the environment is real.
And here is how we actually onboarded our first customer.
Our first customer was a SaaS company that wanted to automatically generate and maintain integration tests for every pull request. This wasn't a plug-and-play onboarding. Over 18 days, we worked closely with their team to deeply integrate into their engineering workflow. We parsed their entire codebase into a knowledge graph, connected context across their tools, and set up a structured spec layer so agents could operate with consistency. Instead of jumping to full rollout, we started with a focused pilot across five engineers, iterated based on real usage, and only then expanded across the team.
What became clear during this process was that onboarding doesn't end at deployment, it ends at adoption. The final four days were spent purely on training and driving usage, ensuring engineers actually integrated the system into their day-to-day work. Because in practice, it doesn't matter if a tool is technically integrated, what matters is how many engineers actively use it. That is the metric that determines whether a product becomes embedded in the workflow or quietly gets sidelined.
As adoption grew, the scope of usage expanded beyond the initial testing use case. What started as automated integration test generation gradually extended into multiple parts of the software development lifecycle, from debugging and RCA to design and implementation workflows. By focusing on real usage and not just deployment, this engagement evolved from a narrow pilot into a broader, long-term partnership, with the system becoming a consistent layer across the team's engineering processes.
" height="176.48689063250688px" id="t2zO9Quc7" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="1.55" stroke="rgb(180, 209, 63)" transform="translate(0.773 0.758)" width="307.0499654602649px"/></svg>)
" height="127.83155915492955px" id="F7uNl9dyd" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(8.021 100.549)" width="136.10429429577454px"/><path d="M 120.738 0 L 166.541 2.512 L 302.646 81.116 L 259.995 105.741 L 140.463 174.742 L 48.783 121.822 L 39.844 116.65 L 21.917 106.308 L 4.359 96.162 L 0 69.714 Z M 84.883 90.646 L 93.847 95.818 L 111.75 106.16 L 140.734 122.881 L 155.534 97.468 L 158.883 91.73 L 212.812 81.264 L 161.197 51.467 L 141.177 39.918 L 130.096 46.32 L 124.653 49.473 L 69.099 81.535 Z M 27.753 84.712 L 130.096 25.635 L 146.718 16.031 L 130.096 15.292 L 26.472 75.132 Z" fill="rgb(0, 53, 51)" height="174.74215475179432px" id="XL4eRTHOZ" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(3.647 4.386)" width="302.6461113816823px"/><path d="M 0 0 L 0 10.343 L 16.622 0.739 Z" fill="rgb(0, 53, 51)" height="10.34275225352113px" id="cBwRaCSIs" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(133.76 19.669)" width="16.622023943661958px"/><path d="M 0 59.84 L 1.28 69.419 L 103.623 10.343 L 103.623 0 Z" fill="rgb(0, 53, 51)" height="69.41898253521126px" id="yI1DYW3PI" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(30.132 19.669)" width="103.62314999999992px"/><path d="M 0 0 L 0 49.251 L 14.357 57.55 L 17.706 51.812 L 71.636 41.346 L 20.021 11.549 Z" fill="rgb(0, 53, 51)" height="57.54972676056339px" id="swIgz6ZQs" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(144.827 44.294)" width="71.63555704225351px"/><path d="M 0 41.617 L 15.785 50.728 L 24.748 55.9 L 42.651 66.242 L 72.078 49.251 L 72.078 0 L 60.997 6.403 L 55.555 9.555 Z" fill="rgb(0, 53, 51)" height="66.2424190140845px" id="Ou0foMTnv" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(72.761 44.294)" width="72.07816690140838px"/><path d="M 0 93.626 L 0 142.877 L 162.183 49.251 L 162.183 0 L 119.532 24.626 Z" fill="rgb(0, 53, 51)" height="142.87681267605637px" id="F6Glizjhy" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(144.11 85.495)" width="162.1830021126761px"/><path d="M 0 0 L 0 49.251 L 4.359 75.699 L 4.359 26.448 Z" fill="rgb(0, 53, 51)" height="75.69868943661974px" id="CEJbzDHVA" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(3.661 74.105)" width="4.358684366197165px"/></svg>)
" height="275.2348071827544px" id="tOCVqXAMo" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.05" stroke="rgb(180, 209, 63)" transform="translate(2.023 1.876)" width="306.08189403973506px"/></svg>)
" height="272.22086421478906px" id="PPsuL8gM9" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.04" stroke="rgb(180, 209, 63)" transform="translate(2.016 1.798)" width="306.4324539473682px"/></svg>)
" height="176.48689063250686px" id="YZ_qP17EP" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="1.55" stroke="rgb(180, 209, 63)" transform="translate(0.773 0.758)" width="307.04996546026496px"/><g d="M 62.549 28.787 C 62.536 28.761 62.526 28.736 62.519 28.709 C 62.535 28.768 62.56 28.824 62.6 28.878 C 62.578 28.849 62.562 28.818 62.549 28.787 Z M 62.549 28.787 L 62.6 28.878 C 62.56 28.824 62.535 28.768 62.519 28.709 Z M 54.656 27.136 L 53.678 29.273 C 52.829 31.129 53.725 33.105 56.041 34.482 L 67.491 41.285 L 70.928 43.27 C 73.406 44.7 77.049 45.237 80.421 44.654 L 121.141 37.611 C 120.159 39.696 120.291 41.929 121.582 44.003 C 125.001 49.499 120.112 55.555 110.627 57.574 C 105.569 58.649 101.585 60.95 99.722 63.869 C 96.226 69.347 85.734 72.169 76.215 70.194 C 71.142 69.142 65.525 69.424 60.847 70.967 C 52.07 73.864 40.885 72.132 35.787 67.087 C 33.07 64.398 28.45 62.529 23.146 61.975 C 13.195 60.934 6.552 55.458 8.262 49.704 C 9.172 46.637 7.711 43.493 4.263 41.1 C -2.205 36.611 -1.202 29.951 6.515 26.18 C 10.627 24.17 13.008 21.221 13.03 18.11 C 13.07 12.271 21.254 7.547 31.367 7.524 C 36.757 7.511 41.866 6.135 45.347 3.761 C 50.795 0.044 59.728 -0.975 67.055 0.959 Z M 121.101 29.063 C 121.295 29.225 121.319 29.421 121.365 29.811 C 121.437 30.422 121.416 31.043 121.303 31.658 C 121.245 31.973 121.216 32.132 121.07 32.303 C 120.952 32.442 120.731 32.596 120.516 32.689 C 120.25 32.804 119.941 32.858 119.324 32.965 L 78.041 40.112 C 77.569 40.193 77.056 40.118 76.707 39.917 L 73.268 37.93 C 72.552 37.516 72.859 36.812 73.828 36.645 L 118.972 28.911 C 119.692 28.787 120.052 28.726 120.384 28.774 C 120.655 28.814 120.941 28.93 121.101 29.063 Z M 77.422 5.057 L 85.829 15.345 L 85.834 15.352 C 85.944 15.485 85.999 15.553 86.076 15.611 C 86.144 15.664 86.226 15.711 86.317 15.751 C 86.42 15.796 86.54 15.83 86.779 15.895 L 107.021 21.407 L 107.041 21.413 C 107.775 21.613 108.144 21.713 108.236 21.838 C 108.316 21.947 108.297 22.073 108.187 22.173 C 108.059 22.288 107.655 22.352 106.863 22.48 L 64.254 29.318 C 63.803 29.4 63.362 29.338 63.037 29.193 L 62.989 29.169 C 62.826 29.09 62.694 28.987 62.61 28.87 L 62.559 28.779 L 62.529 28.701 C 62.501 28.597 62.509 28.489 62.561 28.376 L 73.706 5.239 L 73.713 5.226 C 74.151 4.315 74.371 3.857 74.769 3.71 C 75.115 3.582 75.548 3.562 75.927 3.654 C 76.364 3.761 76.717 4.193 77.422 5.057 Z" fill="transparent" height="72.36999344346039px" id="PThBnjLXo" transform="translate(95.525 49.205)" width="122.67217843649964px"><path d="M 0.03 0.077 C 0.017 0.052 0.007 0.027 0 0 C 0.016 0.059 0.041 0.115 0.081 0.169 C 0.059 0.139 0.043 0.109 0.03 0.077 Z" fill="rgb(180, 209, 63)" height="1px" id="FZhYXbO6L" transform="translate(62.519 28.709)" width="1px"/><path d="M 62.549 28.787 L 62.6 28.878 C 62.56 28.824 62.535 28.768 62.519 28.709 Z M 54.656 27.136 L 53.678 29.273 C 52.829 31.129 53.725 33.105 56.041 34.482 L 67.491 41.285 L 70.928 43.27 C 73.406 44.7 77.049 45.237 80.421 44.654 L 121.141 37.611 C 120.159 39.696 120.291 41.929 121.582 44.003 C 125.001 49.499 120.112 55.555 110.627 57.574 C 105.569 58.649 101.585 60.95 99.722 63.869 C 96.226 69.347 85.734 72.169 76.215 70.194 C 71.142 69.142 65.525 69.424 60.847 70.967 C 52.07 73.864 40.885 72.132 35.787 67.087 C 33.07 64.398 28.45 62.529 23.146 61.975 C 13.195 60.934 6.552 55.458 8.262 49.704 C 9.172 46.637 7.711 43.493 4.263 41.1 C -2.205 36.611 -1.202 29.951 6.515 26.18 C 10.627 24.17 13.008 21.221 13.03 18.11 C 13.07 12.271 21.254 7.547 31.367 7.524 C 36.757 7.511 41.866 6.135 45.347 3.761 C 50.795 0.044 59.728 -0.975 67.055 0.959 Z M 121.101 29.063 C 121.295 29.225 121.319 29.421 121.365 29.811 C 121.437 30.422 121.416 31.043 121.303 31.658 C 121.245 31.973 121.216 32.132 121.07 32.303 C 120.952 32.442 120.731 32.596 120.516 32.689 C 120.25 32.804 119.941 32.858 119.324 32.965 L 78.041 40.112 C 77.569 40.193 77.056 40.118 76.707 39.917 L 73.268 37.93 C 72.552 37.516 72.859 36.812 73.828 36.645 L 118.972 28.911 C 119.692 28.787 120.052 28.726 120.384 28.774 C 120.655 28.814 120.941 28.93 121.101 29.063 Z M 77.422 5.057 L 85.829 15.345 L 85.834 15.352 C 85.944 15.485 85.999 15.553 86.076 15.611 C 86.144 15.664 86.226 15.711 86.317 15.751 C 86.42 15.796 86.54 15.83 86.779 15.895 L 107.021 21.407 L 107.041 21.413 C 107.775 21.613 108.144 21.713 108.236 21.838 C 108.316 21.947 108.297 22.073 108.187 22.173 C 108.059 22.288 107.655 22.352 106.863 22.48 L 64.254 29.318 C 63.803 29.4 63.362 29.338 63.037 29.193 L 62.989 29.169 C 62.826 29.09 62.694 28.987 62.61 28.87 L 62.559 28.779 L 62.529 28.701 C 62.501 28.597 62.509 28.489 62.561 28.376 L 73.706 5.239 L 73.713 5.226 C 74.151 4.315 74.371 3.857 74.769 3.71 C 75.115 3.582 75.548 3.562 75.927 3.654 C 76.364 3.761 76.717 4.193 77.422 5.057 Z" fill="rgb(180, 209, 63)" height="72.36999344346039px" id="AQyCIziS7" transform="translate(0 0)" width="122.67217843649964px"/></g></svg>)
" height="150.90560294117645px" id="jxii70vzV" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(24.37 4.791)" width="261.37546588235216px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.728 3.018 L 116.384 4.988 L 123.793 7.455 L 130.373 10.224 L 136.629 13.481 L 142.286 17.103 L 147.097 20.91 L 151.356 25.179 L 154.784 29.643 L 157.336 34.117 L 159.104 38.936 L 159.995 43.657 L 159.981 48.672 L 159.104 53.438 L 157.336 58.222 L 154.784 62.73 L 151.356 67.194 L 147.128 71.41 L 142.286 75.271 L 136.629 78.892 L 130.373 82.149 L 123.686 84.945 L 116.384 87.386 L 108.728 89.356 L 100.843 90.838 L 92.557 91.859 L 84.164 92.374 L 75.632 92.365 L 67.439 91.859 L 59.322 90.865 L 51.344 89.365 L 43.611 87.386 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.464 L 8.639 67.194 L 5.227 62.775 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.782 L 0.892 38.936 L 2.613 34.25 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.37355058823529px" id="LN6Mj2wjX" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.05 69.207)" width="159.99511058823543px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.729 3.018 L 116.383 4.988 L 123.794 7.455 L 130.374 10.224 L 136.63 13.481 L 142.287 17.103 L 147.098 20.91 L 151.357 25.179 L 154.785 29.643 L 157.337 34.117 L 159.103 38.936 L 159.996 43.657 L 159.979 48.672 L 159.103 53.438 L 157.337 58.222 L 154.785 62.73 L 151.357 67.194 L 147.129 71.41 L 142.287 75.271 L 136.63 78.892 L 130.374 82.149 L 123.687 84.946 L 116.383 87.385 L 108.729 89.355 L 100.843 90.838 L 92.557 91.858 L 84.164 92.374 L 75.632 92.365 L 67.439 91.858 L 59.322 90.864 L 51.344 89.364 L 43.611 87.385 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.463 L 8.639 67.194 L 5.227 62.775 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.781 L 0.892 38.936 L 2.613 34.25 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.37427764705882px" id="jDPtsCydt" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.76 83.833)" width="159.99583764705716px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.728 3.018 L 116.384 4.988 L 123.793 7.455 L 130.373 10.224 L 136.629 13.481 L 142.286 17.103 L 147.097 20.91 L 151.356 25.179 L 154.784 29.643 L 157.336 34.117 L 159.104 38.936 L 159.995 43.657 L 159.981 48.672 L 159.104 53.438 L 157.336 58.222 L 154.784 62.73 L 151.356 67.194 L 147.128 71.41 L 142.286 75.271 L 136.629 78.892 L 130.373 82.149 L 123.686 84.945 L 116.384 87.386 L 108.728 89.356 L 100.843 90.838 L 92.557 91.859 L 84.164 92.374 L 75.632 92.365 L 67.439 91.859 L 59.322 90.865 L 51.344 89.365 L 43.611 87.386 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.464 L 8.639 67.194 L 5.227 62.775 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.782 L 0.892 38.936 L 2.613 34.25 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.37355058823529px" id="UKafYhxUp" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.05 69.207)" width="159.99511058823543px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.728 3.018 L 116.384 4.988 L 123.793 7.455 L 130.373 10.224 L 136.629 13.481 L 142.286 17.103 L 147.097 20.91 L 151.356 25.179 L 154.784 29.643 L 157.336 34.117 L 159.104 38.936 L 159.995 43.657 L 159.981 48.672 L 159.104 53.438 L 157.336 58.222 L 154.784 62.73 L 151.356 67.194 L 147.128 71.41 L 142.286 75.271 L 136.629 78.892 L 130.373 82.149 L 123.686 84.945 L 116.384 87.386 L 108.728 89.356 L 100.843 90.838 L 92.557 91.859 L 84.164 92.373 L 75.632 92.365 L 67.439 91.859 L 59.322 90.865 L 51.344 89.365 L 43.611 87.386 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.463 L 8.639 67.194 L 5.227 62.775 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.781 L 0.892 38.936 L 2.613 34.25 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.3733688235294px" id="BTS7eFR5p" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.05 48.404)" width="159.99511058823543px"/><path d="M 128.886 85.255 L 0 105.189 L 0 19.934 L 128.886 0 Z" fill="transparent" height="105.18923470588237px" id="XpYvdAzW3" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(57.724 4.311)" width="128.88608117646865px"/><path d="M 92.835 53.589 L 92.835 138.028 L 0 84.439 L 0 0 Z" fill="transparent" height="138.02757352941174px" id="K8lS4_UO3" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(192.202 5.927)" width="92.8345058823547px"/><path d="M 30.371 77.481 L 0 142.926 L 0 65.41 L 30.371 0 Z" fill="transparent" height="142.92631411764705px" id="ckGqTr2MB" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(21.656 34.705)" width="30.37088294117827px"/><path d="M 30.371 77.481 L 0 142.928 L 0 65.411 L 30.371 0 Z" fill="transparent" height="142.9275864705882px" id="r3233RfUB" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(254.683 70.769)" width="30.371064705883697px"/><path d="M 92.835 53.589 L 92.835 138.027 L 0 84.439 L 0 0 Z" fill="transparent" height="138.02721000000003px" id="LSrhVSYKp" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(21.656 104.548)" width="92.83486941176557px"/><path d="M 128.886 85.255 L 0 105.19 L 0 19.934 L 128.886 0 Z" fill="transparent" height="105.18959823529411px" id="x2Xopuli2" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(120.064 138.931)" width="128.88626294117825px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.728 3.017 L 116.384 4.988 L 123.793 7.455 L 130.373 10.224 L 136.629 13.481 L 142.286 17.103 L 147.097 20.91 L 151.356 25.179 L 154.784 29.643 L 157.336 34.116 L 159.104 38.936 L 159.995 43.657 L 159.981 48.672 L 159.104 53.438 L 157.336 58.221 L 154.784 62.73 L 151.356 67.194 L 147.128 71.41 L 142.286 75.271 L 136.629 78.892 L 130.373 82.149 L 123.686 84.945 L 116.384 87.385 L 108.728 89.356 L 100.843 90.838 L 92.557 91.859 L 84.164 92.373 L 75.632 92.364 L 67.439 91.859 L 59.322 90.865 L 51.344 89.365 L 43.611 87.385 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.463 L 8.639 67.194 L 5.227 62.774 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.781 L 0.892 38.936 L 2.613 34.249 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.3733688235294px" id="dtqTIoHPq" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.05 30.156)" width="159.99511058823543px"/></svg>)
" width="309px"><path d="M 0 0 C 62.424 52.356 97.323 76.699 124.122 133.612 C 125.774 137.121 129.275 139.414 133.153 139.414 L 178.332 139.414 C 182.27 139.414 185.824 137.027 187.434 133.433 C 220.347 59.939 255.786 56.508 309 0 C 223.902 11.24 92.218 13.79 0 0 Z" fill="rgb(244, 255, 200)" height="139.41414141414143px" id="YPPdTHgjp" width="309px"/></g></svg>)
" width="291.547144895145px"><path d="M 2.159 40.336 L 81.816 193.109 C 85.087 199.382 91.575 203.316 98.649 203.316 L 199.157 203.316 C 206.445 203.316 213.09 199.143 216.257 192.578 L 289.654 40.384 C 294.95 29.401 288.66 16.33 276.702 13.944 C 186.518 -4.05 102.962 -5.096 14.535 13.537 C 2.503 16.072 -3.526 29.434 2.159 40.336 Z" fill="rgb(174, 218, 0)" height="203.31595618278868px" id="beF0XCFO6" transform="translate(0 0)" width="291.54714489452647px"/></g></svg>)
" width="279.949712674067px"><path d="M 1.851 35.23 L 64.467 192.416 C 68.34 202.139 77.749 208.518 88.214 208.518 L 194.612 208.518 C 205.187 208.518 214.67 202.007 218.469 192.138 L 278.208 36.927 C 285.378 18.296 269.348 -1.055 249.578 1.717 C 168.185 13.131 109.4 10.303 29.167 0.211 C 9.712 -2.236 -5.406 17.013 1.851 35.23 Z" fill="rgb(145, 181, 0)" height="208.51809526570761px" id="tGoxWLGVd" transform="translate(0 0)" width="279.94971259877605px"/></g></svg>)
Recommended Blogs






























