


Introduction: The Agent Evaluation Gap
While standard Large Language Model benchmarks like HumanEval or MBPP provided early baselines, production deployment of software engineering agents has exposed a persistent realism gap in evaluation. Research by Jimenez et al. demonstrates that resolving real-world GitHub issues requires fundamentally different capabilities than traditional coding benchmarks test, with even state-of-the-art models achieving only 1.96% accuracy on repository-level tasks without specialized agent scaffolding.
As of early 2026, the community has pivoted toward more rigorous, repository-level frameworks. The release of SWE-Bench+ and the Unified Software Engineering Benchmark (USEbench) highlight that agents often struggle with Repository Intelligence: the ability to understand not just isolated lines of code, but the temporal history and complex inter-dependencies of a codebase. Even high-performing agents on the SWE-bench Verified leaderboard frequently fail when faced with the mutation-based realism, coding standards and underspecified queries characteristic of actual developer workflows.
Success in these environments depends on an agent's ability to navigate cross-file dependencies, adhere to project-specific architectural patterns, and maintain state across long-running trajectories. At Potpie, our objective was to establish a systematic testing framework that accurately quantifies an agent's utility at the repository level. We required evaluation data that challenged three distinct cognitive functions:
QA Agent: Retrieval-based reasoning over deep dependency graphs.
CodeGen Agent: Context-aware synthesis that integrates with existing project types and utilities.
Debugger Agent: Fault localization and "fail-to-pass" trajectory resolution as seen in the GitTaskBench framework.
To build a reliable evaluation suite, we had to move beyond static snippets to create a dynamic data pipeline that mirrors the complexity of production software. This article outlines the technical methodologies we employed to automate the creation of this testing data, the failures we encountered with early synthetic approaches, and the refined architecture we currently use to benchmark our agentic workflows.
Why Open Datasets didn’t work for us
The initial phase of our evaluation strategy involved auditing existing open-source benchmarks. However, we found that most were insufficient for testing repository-level agents due to four primary technical failures: data contamination, lack of execution-based verification, the absence of cross-file context, and a lack of trajectory data.
The most significant hurdle is benchmark leakage. Standard datasets like HumanEval and MBPP have existed for years; their solutions are extensively present in the training corpora of modern LLMs. Research from the Epoch AI suggests that high performance on these benchmarks often correlates more with memorization than with genuine reasoning. For agents designed to solve novel engineering problems, a dataset where the model already knows the answer is scientifically useless. Li et al. further validate this through DevEval, a benchmark of 1,874 real-world repository tasks, where even GPT-4-turbo achieves only 53% Pass@1—highlighting the vast gap between synthetic benchmarks and production codebases.
Open datasets typically focus on atomic functions. For example, a prompt might ask an agent to "implement a function that reverses a linked list." In a production environment, an engineer rarely works in such isolation. Evidence from SWE-Bench+ shows that agents which score 90%+ on isolated coding tasks often drop to sub 20% when the solution requires cross-file reasoning. This gap is further emphasized by Xia et al., who demonstrate that a simple three-phase debugging process (localization, repair, validation) without complex tool integrations achieves 32% on SWE-bench Lite, outperforming sophisticated agentic approaches at a fraction of the cost ($0.70 per bug). Real repository-level tasks demand:
Dependency Awareness: Understanding how changing a utility function in
lib/utils.pybreaks a schema validation inapi/routes.py.Architectural Adherence: Following specific patterns (e.g., dependency injection or logging wrappers) that are unique to that codebase.
Environmental Parity: Most open datasets lack a containerized execution environment. Without the ability to run
pytestornpm testagainst the agent's changes, the "Ground Truth" remains theoretical rather than functional.
Open datasets often provide gold-standard prompts that are too clean. In practice, developer issues are messy, underspecified, or even contradictory. USEbench identified that agents fail most frequently when they have to infer intent from an ambiguous bug report, a scenario that HumanEval-style benchmarks ignore.
To improve our agents, we didn't just need to know if they failed but how they failed. Existing datasets provided static Input/Output pairs but lacked the intermediate trajectories. The trajectories contain a sequence of terminal commands, file reads, and edits an agent performs. Without this data, we could not perform the fine-grained error analysis necessary to iterate on our CodeGen, and Debugger agents.
This forced us to conclude that for Potpie's specific needs, we had to move from relying on open datasets to generating them via a purpose-built synthetic pipeline.
Repo Selection
To ensure our synthetic data retained the entropy and structural complexity of production software, we curated a diverse set of high-scale open-source repositories. The selection was based on four criteria: linguistic diversity, architectural complexity, presence of external service integrations, and the use of non-trivial design patterns.
Our evaluation suite utilizes the following core repositories:
VS Code (TypeScript/C++): Provides a massive monorepo environment with complex event loops, asynchronous IPC, and strict architectural boundaries.
Apache Airflow (Python): Offers a multi-service distributed system context, involving complex workflow DAGs, database migrations, and integration with a vast ecosystem of third-party operators.
Mattermost (Go/React): A classic client-server architecture with high-concurrency requirements and complex state synchronization between the backend and the frontend.
Supabase (PostgreSQL/TypeScript/Go): Tests the agent's ability to reason across database schemas, real-time engines, and infrastructure-as-code patterns.
Tinygrad (Python/C): A minimalist yet mathematically dense deep-learning framework that challenges the agent's understanding of low-level optimization, compiler backends, and tensor abstractions.
By utilizing this diverse selection of projects, we ensured that our agents moved beyond language-specific optimizations toward a broader Repository Intelligence capable of navigating heterogeneous service boundaries and intricate dependency structures.
QA Agent: Multi-hop Retrieval & Graph Analysis
The QA Agent is designed to function as a deep-reasoning interface for the entire codebase. Unlike standard documentation search or symbol lookup tools, this agent must reconcile high-level architectural intent with granular implementation details across heterogeneous modules.
Our primary goal in building these evaluations was to move beyond single-shot queries. We specifically sought to eliminate cases where an agent could provide a correct answer through simple keyword matching, pattern recognition, or memorized documentation from its training set. To achieve this, we explicitly disregarded several standard techniques:
Vector DB Similarity Search Checks: We ignored simple retrieval tasks where the query closely matched a chunk of code. These tasks only test the embedding model's quality, not the agent's ability to reason about the code's logic or state.
Symbol Definition Lookup: We avoided questions that could be answered by a simple LSP-style "Go to Definition.". Static analysis tools already solve this; we wanted to test the agent's ability to understand the semantics of the symbol's usage across call sites.
Standard Boilerplate Identification: We disregarded questions about common framework structures (e.g., "Where are the routes defined in this Express app?"). High-frequency patterns are overrepresented in LLM training data, leading to inflated scores through memory rather than active code comprehension.
During our iterations, certain techniques that theoretically seemed robust produced poor evaluation results:
Auto-generated Javadoc/Docstring Summarization: We attempted to feed a model all project docstrings and ask it to generate summaries. Counterintuitively, this made the evaluations easier for agents. The summaries acted as cheatsheets that bypassed the need for the agent to read the actual source code, resulting in high scores that collapsed when the summaries were removed.
Cyclomatic Complexity-based Sampling: We tried targeting the most "complex" functions based on cyclomatic complexity metrics. While these functions were hard to read, they were often self-contained (e.g., a massive
switchstatement). They did not challenge the agent's ability to navigate relationships between files, which is where agents actually struggle.Random Walk Graph Traversal: We tried generating questions by randomly traversing the dependency graph. This produced "hallucinated connections." Without anchoring the traversal in a functional logic flow (like a specific user request path), the questions became nonsensical or asked about dependencies that were technically present but logically irrelevant to the system's runtime behavior.
While our initial version of QA pairs generation relied heavily on static AST-based dependency mapping, we pivoted toward a more dynamic, agent-centric discovery model to capture the true complexity of modern software architectures.
The foundation of our analysis remains the extraction of the Abstract Syntax Tree (AST) to construct a global dependency graph. This provides the structural skeleton of the repository, mapping function calls, type inheritances, and service injections. However, static analysis alone often fails to highlight the hot paths or logical bottlenecks that define runtime behaviour. Recent work by Ouyang et al. demonstrates that repository-level code graphs significantly enhance agent performance, achieving new state-of-the-art results among open-source frameworks on SWE-bench through structured navigation of cross-file dependencies. Similarly, DraCo uses dataflow-guided retrieval augmentation to help LLMs identify relevant code entities across different files, addressing the fundamental challenge that agents struggle most not with reading individual functions, but with understanding relationships between files.
To overcome the limitations of static mapping, we integrated specialized services like Zread and DeepWiki to perform deep contextual reads of the repository, identifying areas with high logical density and interdependent service boundaries that are often missed by standard parsers. This approach aligns with CodeNav, which demonstrates that agents can effectively navigate and leverage previously unseen codebases through automatic indexing and iterative code search without manual tool registration. We use Model Context Protocols (MCPs — standardized interfaces for model-tool interaction) to generate a list of critical bottleneck modules and what are the suggested topics for this module and its interactions. Once these critical bottlenecks have been identified, we employ a multi-stage generation process:
Primary Generation: A teacher model generates raw questions based on the identified bottleneck logic.
Question Layering: We layer these questions by introducing additional constraints or requiring information from distant modules. This ensures the answer is not contained within a single context window but is distributed across the repository's architecture.
Deduplication: The final stage of the generation pipeline involves a rigorous deduplication pass. We filter the candidate list to remove redundant queries, ensuring that every question in the evaluation set targets a unique logic path or architectural intersection.
To maintain the Golden Set integrity (human-verified ground truth data used as the definitive correct answer), every generated QA pair undergoes a two-step validation process before ingestion:
Graph Path Verification: A validator script ensures that the files referenced in the correct answer are indeed connected via the AST-extracted dependency graph.
Ambiguity Heuristics: If a query could be interpreted in multiple ways based on available symbols, the system mandates further specificity in the prompt.

CodeGen Agent: Integration Fidelity and Multi-Stage Filtering
The evaluation of Code Generation (CodeGen) agents centers on Integration Fidelity, which we define as the agent's capacity to synthesize new functional logic while strictly adhering to project-specific abstractions, internal APIs, and architectural constraints. Achieving this benchmark requires a comprehensive assessment of how generated code integrates within a dense dependency graph. Recent work by Pan et al. introduces SWE-Gym, the first environment for training real-world software engineering agents with 2,438 Python task instances, demonstrating that fine-tuning on repository-level tasks achieves up to 19% absolute performance gains, validating our approach of mining actual GitHub PRs rather than using synthetic function-level benchmarks.
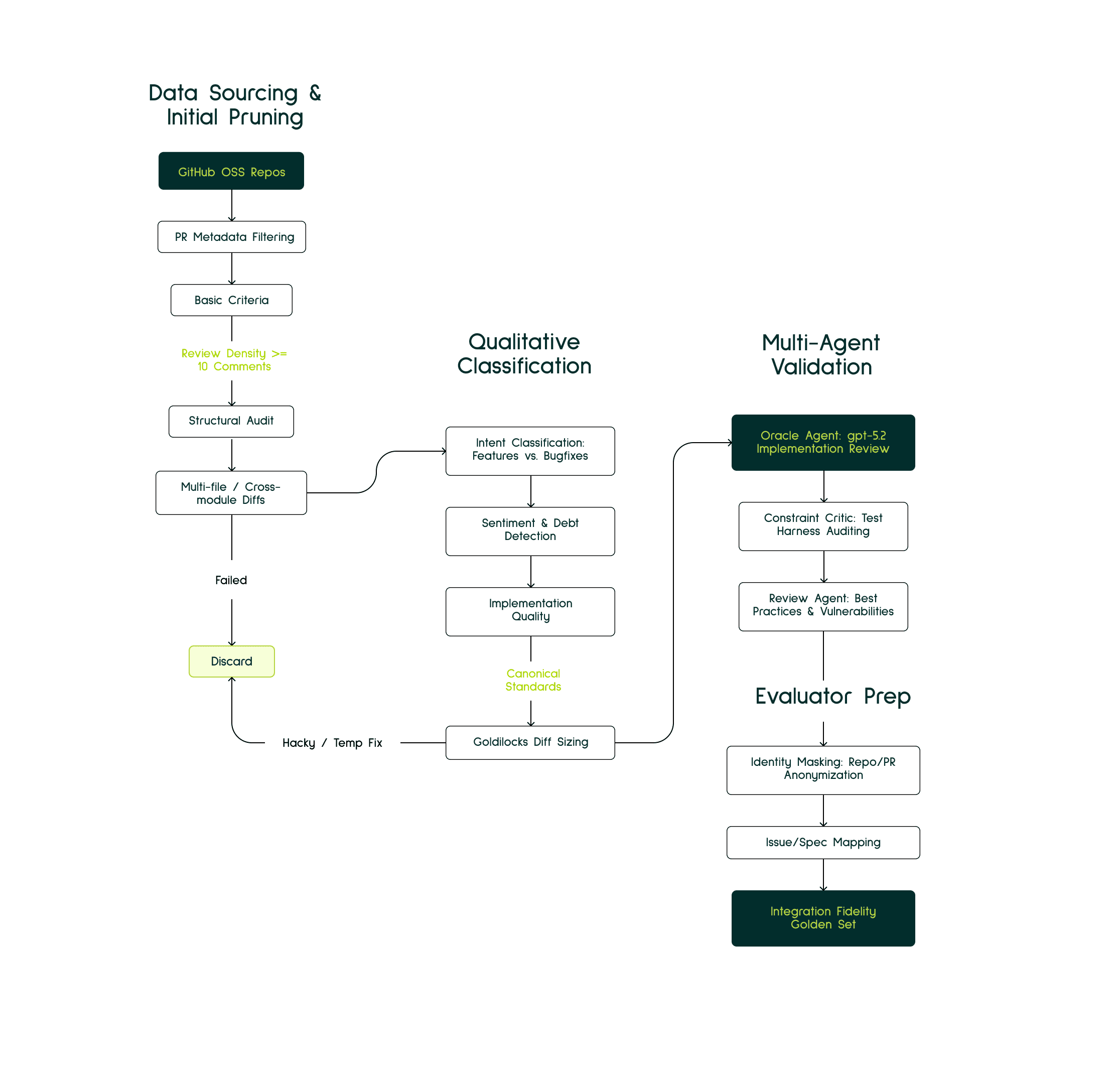
Our evaluation data is curated using an automated agentic pipeline designed to mine high-quality Pull Requests (PRs) from popular open source and open license GitHub repositories. To isolate instances representing substantial engineering effort, we apply a multi-stage filtering process. Initially, unsuitable candidates are pruned based on repository activity, PR metadata and the complexity of code differences. Next, heuristic checks are applied to assess the commit's intended purpose, the sentiment expressed by reviewers, and the presence of technical debt. This is followed by an Oracle Agent (a higher-capability model used as a ground-truth reference validator) and Reviewer agents working to confirm the canonical implementation's validity and the fairness of the associated tests. The final stage is an expert review dedicated to ensuring a precise semantic alignment between the initial prompt and the delivered code solution.
The initial step looks like this:
Review-Density and Peer Scrutiny: We prioritize PRs that have undergone significant human review, specifically filtering for those with a minimum of ten independent comments or reviews. This metric ensures that the implementation has survived rigorous debate and follows the project's consensus on code quality.
Architectural Breadth: To guarantee cross-module complexity, we select only those PRs that necessitate changes across multiple files or service boundaries. This prevents the evaluation from devolving into trivial single-file synthesis tasks.
Goldilocks Diff Sizing: We filter for a balanced diff size neither too small (lacking context) nor too large (exceeding context windows). PRs that are too small lack sufficient context for testing repository intelligence, while sprawling refactors exceeding several thousand lines are often too large for current context windows and lack the targeted feature-focus required for specific evaluation. In the end we settled around 300-1500 line PR changes.
Metadata and Spec Integrity: We mandate that each PR be linked to a structured Issue containing a detailed What and Why description. This provides the agent with a realistic starting point: a feature request or issue report without leaking the implementation details.
Temporal Stability and Commit Auditing: We perform a post-merge audit of the repository's history. If the target lines were fundamentally refactored or reverted shortly after merging, the PR is discarded. This ensures that our golden truth remains stable and represents code that successfully entered production.
We pass these candidate PRs to an agentic pipeline that helps us filter nuances like intent and tech debit which are invisible to static metrics. During Intent Classification, we leverage models to differentiate between targeted feature additions, bug fixes, and sprawling refactors, explicitly prioritizing features that introduce novel logic within established service boundaries. Simultaneously, we perform Sentiment and Debt Detection by parsing the entire review thread. This allows us to detect hidden contexts such as reviewers noting that a merge is a temporary hack or identifying edge cases that were intentionally deferred. By quantifying this Implementation Debt, we can weigh the actual difficulty of the task and disqualify PRs that represent incomplete or sub-optimal solutions, thereby ensuring our ground truth is representative of canonical engineering standards.
To ensure the Golden Truth is optimal, we utilize a two-agent verification system:
Oracle Agent: A superior model (GPT-5.2) reviews the human implementation against the PR description and repository structure and patterns to identify if the code is the canonical way of solving the problem within the project's specific idioms. This serves as our ground-truth validator — following the ML convention where an "oracle" provides the definitive reference answer.
Constraint Critic Agent: This agent audits the associated test harness. Its primary role is to identify and strip away overspecified constraints such as rigid mock expectations or arbitrary implementation-specific assertions that might lead the evaluation system to reject a functionally sound and logically correct alternative. This mitigates the risk of false negatives, such as the previously mentioned Django fail cases, where valid reasoning is penalized by brittle testing infrastructure.
Review Agent: We use this agent to review if the code is following the code best practices and doesn’t have any code vulnerabilities. This agent has the ability to look into the future commits, PRs and discussions associated with this diff to make well informed decisions about the quality of the code.
Throughout our data generation process, we intentionally disregarded Isolated Function Synthesis and Template-Based Generation, as these modalities obscure an agent's propensity for architectural errors and dependency hallucinations. A common failure mode we identified was the standard library trap, which occurs when agents produce syntactically correct code using generic libraries (e.g., requests) in environments that strictly mandate custom internal wrappers. Additionally, to prevent trivializing the task through context leakage, we systematically mask project titles, PR identifiers, and specific naming conventions within the synthesized prompts, forcing the agent to rely on active code discovery rather than pattern memory.
Debugger Agent: Fault Localization and Trajectory Evaluation
The Debugger Agent is designed to operate in the high-entropy environment of production failures, where the path from symptom to solution is rarely linear. Unlike QA agents that query static knowledge or CodeGen agents that synthesize new functionality, the Debugger must navigate through ambiguous error signals, incomplete context, and cascading failures to identify the minimal viable fix. This challenge of autonomous program repair has gained significant research attention, with Bouzenia et al. introducing RepairAgent: the first autonomous LLM-based repair system that interleaves bug information gathering with validation, successfully repairing 164 bugs on Defects4J at a cost of only 14 cents per bug using GPT-3.5.
Our primary goal in building these evaluations was to move beyond simplistic "spot the typo" tasks. We specifically sought to eliminate cases where an agent could succeed through shallow pattern matching or trivial syntax correction. To achieve this, we explicitly disregarded several standard techniques:
Static Bug Injection: We avoided artificially injecting bugs (e.g., swapping operators, deleting lines) into existing code. While easy to generate, these synthetic bugs lack the contextual complexity of real failures—the subtle interaction between multiple modules, the race condition that only manifests under specific load, or the configuration drift that breaks assumptions three levels deep in the call stack.
Single-File Debugging Scenarios: We disregarded test cases confined to a single file or function. In production, bugs rarely respect file boundaries. A null pointer in the API layer might originate from a schema validation issue in the models, which traces back to a migration change in the database layer. Isolated debugging tests create a false sense of capability.
Error-Only Evaluation: We rejected evaluations that only provided stack traces without the surrounding context. Real debugging requires understanding the environment state: recent deployments, configuration changes, dependency versions, and system logs. Agents need to reason about why the code reached a failure state, not just where.
During our iterations, certain techniques that theoretically seemed robust produced poor evaluation results:
Commit-Message-Based Bug Classification: We initially attempted to categorize bugs using the commit messages from fix commits (e.g., "fix race condition," "patch memory leak"). Counterintuitively, this introduced significant bias. Developers often mischaracterize bugs—what they call a "quick fix" might involve deep architectural changes, while a "major refactor" might just be renaming variables. Relying on subjective human descriptions led to inconsistent difficulty distributions.
Test-Delta-Based Ground Truth: We tried using the test files modified in a fix commit as the definitive oracle for what needed to change. However, we discovered that many PRs include tangential test updates, adding coverage for unrelated features, updating mocks to match new interfaces, or refactoring test utilities. This noise made it impossible to isolate the specific behavioural change that constituted the actual bug fix.
Silent Failure Inclusion: We experimented with including silent bugs, issues that didn't produce explicit errors but caused incorrect behaviour (e.g., off-by-one errors in pagination, incorrect currency conversions). These proved impossible to evaluate reliably. Without a clear failure signal, we couldn't verify that the Debugger Agent had actually identified the root cause versus making an unrelated change that happened to pass the tests.
While our initial version relied on simple git-diff analysis to identify bug-fix commits, we pivoted toward a more rigorous, execution-based validation model that treats historical commits as reproducible forensic evidence.
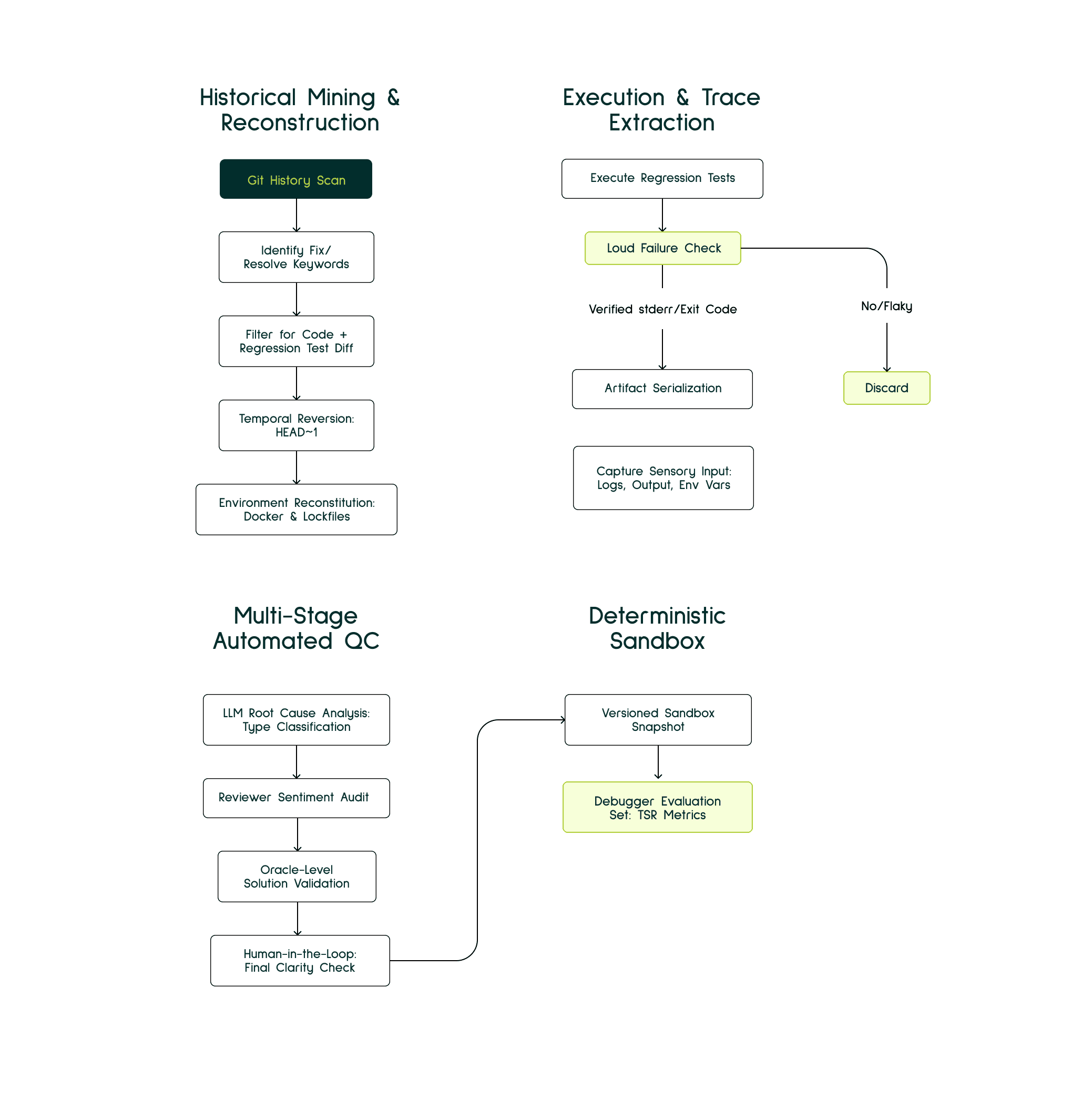
The foundation of our pipeline is the Fail-to-Pass commit pattern: a well-established concept in automated program repair where a commit transitions the codebase from a failing test state to a passing one. This approach aligns with AutoCodeRover, which demonstrated at NeurIPS 2024 that AST-based context retrieval followed by patch generation effectively resolves GitHub-scale issues through structured program analysis. However, simply identifying these commits is insufficient. We simulate the high-entropy state of real production failures through a rigorous operational sequence:
Temporal Reversion: We rewind the repository to the
HEAD~1state—the exact moment the bug existed but before the fix was applied. This captures the authentic failure environment, including dependency versions, configuration files, and build tools as they existed at that point in time.Environment Reconstruction: We instantiate a containerized sandbox using repository-native lockfiles (
package-lock.json,poetry.lock,Cargo.lock) and Docker configurations from that historical moment. This ensures environmental parity—evaluating the agent against the same OS, compiler, and dependency tree that the original developers faced.Loud Failure Verification: We execute the regression test suite to verify that the bug produces a "Loud Failure": a verifiable error characterized by non-zero exit codes, explicit exception messages, or clear stderr stack traces. Silent failures (tests that pass but check wrong assertions, or behavioural bugs without error signals) are discarded. This constraint ensures we can objectively verify when the Debugger Agent has successfully identified and resolved the issue.
Sensory Input Extraction: We serialize the complete failure context—terminal output, build logs, environment variables, recent git history, and the failing test specifications—to serve as the initial state for the Debugger Agent. This mimics the information asymmetry real developers face: error signals without immediate clarity on root cause.
Once we've extracted valid candidates, we subject them to Multi-Stage Automated Quality Control:
LLM Root Cause Analysis (RCA): An LLM agent classifies the bug type, differentiating between surface-level issues (syntax errors, missing imports) and deep logical flaws (race conditions, algorithmic errors, architectural mismatches). This ensures our evaluation set spans the full spectrum of debugging difficulty.
Reviewer Sentiment Audit: We parse the original PR conversation to detect contextual signals. Comments indicating "this is a temporary hack," "we should refactor this later," or security concerns trigger disqualification. We only accept fixes that represent canonical, production-ready solutions.
Oracle-Level Solution Validation: An Oracle Agent evaluates whether a proposed fix trajectory is semantically equivalent to the human-verified solution. This checks that the agent isn't just making the tests pass through arbitrary changes, but is actually addressing the root cause in a way that aligns with the codebase's architectural patterns.
Human-in-the-Loop (Final Verification): Human experts review the synthesized bug report to ensure it's clear enough for a human developer to solve. This validates that the test is technically fair and the failure signal provides sufficient information for root cause identification.
Our evaluation metric, Trajectory Success Rate (TSR), acknowledges that successful debugging is multidimensional:
The Automated Validation Layer
To trust our synthetic pipeline, we implemented an automated validation layer that acts as a gatekeeper before any evaluation instance enters the Golden Set. This layer performs three critical checks:
Semantic Parity: Using cross-model consensus, we verify that the generated User Query logically leads to the Ground Truth code. If two independent models (e.g., Opus 4.5 and GPT-5.2) cannot reach the same conclusion, the instance is flagged for human review.
Environment Health Check: Before an agent is tested, a pre-flight script executes in the Dockerized sandbox to ensure all dependencies are resolved and the "Loud Failure" is indeed reproducible.
Prompt Leakage Scan: We run a specific pass to ensure the prompt does not contain leakage identifiers, file paths, or function names that effectively give away the solution.
Current Status and Future Roadmap
The pipeline is currently 70% automated. We trigger Data Mining sprints monthly to refresh the Golden Set, ensuring our agents are tested against the latest patterns in our core repositories.
Looking forward, we are integrating Self-Play Reinforcement Learning, where agents generate increasingly difficult test cases for one another, creating an adversarial loop that continuously raises the ceiling for Repository Intelligence. Recent breakthrough work by Wei et al. from Meta FAIR introduces Self-play SWE-RL (SSR), demonstrating that agents can generate training data through adversarial self-play without human curation, training software engineering agents to super intelligent levels by having them compete to generate and solve increasingly complex repository-level tasks. This aligns with our vision of a continuously evolving evaluation framework where the difficulty adapts to agent capabilities.
" height="176.48689063250688px" id="t2zO9Quc7" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="1.55" stroke="rgb(180, 209, 63)" transform="translate(0.773 0.758)" width="307.0499654602649px"/></svg>)
" height="127.83155915492955px" id="F7uNl9dyd" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(8.021 100.549)" width="136.10429429577454px"/><path d="M 120.738 0 L 166.541 2.512 L 302.646 81.116 L 259.995 105.741 L 140.463 174.742 L 48.783 121.822 L 39.844 116.65 L 21.917 106.308 L 4.359 96.162 L 0 69.714 Z M 84.883 90.646 L 93.847 95.818 L 111.75 106.16 L 140.734 122.881 L 155.534 97.468 L 158.883 91.73 L 212.812 81.264 L 161.197 51.467 L 141.177 39.918 L 130.096 46.32 L 124.653 49.473 L 69.099 81.535 Z M 27.753 84.712 L 130.096 25.635 L 146.718 16.031 L 130.096 15.292 L 26.472 75.132 Z" fill="rgb(0, 53, 51)" height="174.74215475179432px" id="XL4eRTHOZ" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(3.647 4.386)" width="302.6461113816823px"/><path d="M 0 0 L 0 10.343 L 16.622 0.739 Z" fill="rgb(0, 53, 51)" height="10.34275225352113px" id="cBwRaCSIs" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(133.76 19.669)" width="16.622023943661958px"/><path d="M 0 59.84 L 1.28 69.419 L 103.623 10.343 L 103.623 0 Z" fill="rgb(0, 53, 51)" height="69.41898253521126px" id="yI1DYW3PI" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(30.132 19.669)" width="103.62314999999992px"/><path d="M 0 0 L 0 49.251 L 14.357 57.55 L 17.706 51.812 L 71.636 41.346 L 20.021 11.549 Z" fill="rgb(0, 53, 51)" height="57.54972676056339px" id="swIgz6ZQs" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(144.827 44.294)" width="71.63555704225351px"/><path d="M 0 41.617 L 15.785 50.728 L 24.748 55.9 L 42.651 66.242 L 72.078 49.251 L 72.078 0 L 60.997 6.403 L 55.555 9.555 Z" fill="rgb(0, 53, 51)" height="66.2424190140845px" id="Ou0foMTnv" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(72.761 44.294)" width="72.07816690140838px"/><path d="M 0 93.626 L 0 142.877 L 162.183 49.251 L 162.183 0 L 119.532 24.626 Z" fill="rgb(0, 53, 51)" height="142.87681267605637px" id="F6Glizjhy" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(144.11 85.495)" width="162.1830021126761px"/><path d="M 0 0 L 0 49.251 L 4.359 75.699 L 4.359 26.448 Z" fill="rgb(0, 53, 51)" height="75.69868943661974px" id="CEJbzDHVA" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.46" stroke="rgb(180, 209, 63)" transform="translate(3.661 74.105)" width="4.358684366197165px"/></svg>)
" height="275.2348071827544px" id="tOCVqXAMo" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.05" stroke="rgb(180, 209, 63)" transform="translate(2.023 1.876)" width="306.08189403973506px"/></svg>)
" height="272.22086421478906px" id="PPsuL8gM9" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2.04" stroke="rgb(180, 209, 63)" transform="translate(2.016 1.798)" width="306.4324539473682px"/></svg>)
" height="176.48689063250686px" id="YZ_qP17EP" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="1.55" stroke="rgb(180, 209, 63)" transform="translate(0.773 0.758)" width="307.04996546026496px"/><g d="M 62.549 28.787 C 62.536 28.761 62.526 28.736 62.519 28.709 C 62.535 28.768 62.56 28.824 62.6 28.878 C 62.578 28.849 62.562 28.818 62.549 28.787 Z M 62.549 28.787 L 62.6 28.878 C 62.56 28.824 62.535 28.768 62.519 28.709 Z M 54.656 27.136 L 53.678 29.273 C 52.829 31.129 53.725 33.105 56.041 34.482 L 67.491 41.285 L 70.928 43.27 C 73.406 44.7 77.049 45.237 80.421 44.654 L 121.141 37.611 C 120.159 39.696 120.291 41.929 121.582 44.003 C 125.001 49.499 120.112 55.555 110.627 57.574 C 105.569 58.649 101.585 60.95 99.722 63.869 C 96.226 69.347 85.734 72.169 76.215 70.194 C 71.142 69.142 65.525 69.424 60.847 70.967 C 52.07 73.864 40.885 72.132 35.787 67.087 C 33.07 64.398 28.45 62.529 23.146 61.975 C 13.195 60.934 6.552 55.458 8.262 49.704 C 9.172 46.637 7.711 43.493 4.263 41.1 C -2.205 36.611 -1.202 29.951 6.515 26.18 C 10.627 24.17 13.008 21.221 13.03 18.11 C 13.07 12.271 21.254 7.547 31.367 7.524 C 36.757 7.511 41.866 6.135 45.347 3.761 C 50.795 0.044 59.728 -0.975 67.055 0.959 Z M 121.101 29.063 C 121.295 29.225 121.319 29.421 121.365 29.811 C 121.437 30.422 121.416 31.043 121.303 31.658 C 121.245 31.973 121.216 32.132 121.07 32.303 C 120.952 32.442 120.731 32.596 120.516 32.689 C 120.25 32.804 119.941 32.858 119.324 32.965 L 78.041 40.112 C 77.569 40.193 77.056 40.118 76.707 39.917 L 73.268 37.93 C 72.552 37.516 72.859 36.812 73.828 36.645 L 118.972 28.911 C 119.692 28.787 120.052 28.726 120.384 28.774 C 120.655 28.814 120.941 28.93 121.101 29.063 Z M 77.422 5.057 L 85.829 15.345 L 85.834 15.352 C 85.944 15.485 85.999 15.553 86.076 15.611 C 86.144 15.664 86.226 15.711 86.317 15.751 C 86.42 15.796 86.54 15.83 86.779 15.895 L 107.021 21.407 L 107.041 21.413 C 107.775 21.613 108.144 21.713 108.236 21.838 C 108.316 21.947 108.297 22.073 108.187 22.173 C 108.059 22.288 107.655 22.352 106.863 22.48 L 64.254 29.318 C 63.803 29.4 63.362 29.338 63.037 29.193 L 62.989 29.169 C 62.826 29.09 62.694 28.987 62.61 28.87 L 62.559 28.779 L 62.529 28.701 C 62.501 28.597 62.509 28.489 62.561 28.376 L 73.706 5.239 L 73.713 5.226 C 74.151 4.315 74.371 3.857 74.769 3.71 C 75.115 3.582 75.548 3.562 75.927 3.654 C 76.364 3.761 76.717 4.193 77.422 5.057 Z" fill="transparent" height="72.36999344346039px" id="PThBnjLXo" transform="translate(95.525 49.205)" width="122.67217843649964px"><path d="M 0.03 0.077 C 0.017 0.052 0.007 0.027 0 0 C 0.016 0.059 0.041 0.115 0.081 0.169 C 0.059 0.139 0.043 0.109 0.03 0.077 Z" fill="rgb(180, 209, 63)" height="1px" id="FZhYXbO6L" transform="translate(62.519 28.709)" width="1px"/><path d="M 62.549 28.787 L 62.6 28.878 C 62.56 28.824 62.535 28.768 62.519 28.709 Z M 54.656 27.136 L 53.678 29.273 C 52.829 31.129 53.725 33.105 56.041 34.482 L 67.491 41.285 L 70.928 43.27 C 73.406 44.7 77.049 45.237 80.421 44.654 L 121.141 37.611 C 120.159 39.696 120.291 41.929 121.582 44.003 C 125.001 49.499 120.112 55.555 110.627 57.574 C 105.569 58.649 101.585 60.95 99.722 63.869 C 96.226 69.347 85.734 72.169 76.215 70.194 C 71.142 69.142 65.525 69.424 60.847 70.967 C 52.07 73.864 40.885 72.132 35.787 67.087 C 33.07 64.398 28.45 62.529 23.146 61.975 C 13.195 60.934 6.552 55.458 8.262 49.704 C 9.172 46.637 7.711 43.493 4.263 41.1 C -2.205 36.611 -1.202 29.951 6.515 26.18 C 10.627 24.17 13.008 21.221 13.03 18.11 C 13.07 12.271 21.254 7.547 31.367 7.524 C 36.757 7.511 41.866 6.135 45.347 3.761 C 50.795 0.044 59.728 -0.975 67.055 0.959 Z M 121.101 29.063 C 121.295 29.225 121.319 29.421 121.365 29.811 C 121.437 30.422 121.416 31.043 121.303 31.658 C 121.245 31.973 121.216 32.132 121.07 32.303 C 120.952 32.442 120.731 32.596 120.516 32.689 C 120.25 32.804 119.941 32.858 119.324 32.965 L 78.041 40.112 C 77.569 40.193 77.056 40.118 76.707 39.917 L 73.268 37.93 C 72.552 37.516 72.859 36.812 73.828 36.645 L 118.972 28.911 C 119.692 28.787 120.052 28.726 120.384 28.774 C 120.655 28.814 120.941 28.93 121.101 29.063 Z M 77.422 5.057 L 85.829 15.345 L 85.834 15.352 C 85.944 15.485 85.999 15.553 86.076 15.611 C 86.144 15.664 86.226 15.711 86.317 15.751 C 86.42 15.796 86.54 15.83 86.779 15.895 L 107.021 21.407 L 107.041 21.413 C 107.775 21.613 108.144 21.713 108.236 21.838 C 108.316 21.947 108.297 22.073 108.187 22.173 C 108.059 22.288 107.655 22.352 106.863 22.48 L 64.254 29.318 C 63.803 29.4 63.362 29.338 63.037 29.193 L 62.989 29.169 C 62.826 29.09 62.694 28.987 62.61 28.87 L 62.559 28.779 L 62.529 28.701 C 62.501 28.597 62.509 28.489 62.561 28.376 L 73.706 5.239 L 73.713 5.226 C 74.151 4.315 74.371 3.857 74.769 3.71 C 75.115 3.582 75.548 3.562 75.927 3.654 C 76.364 3.761 76.717 4.193 77.422 5.057 Z" fill="rgb(180, 209, 63)" height="72.36999344346039px" id="AQyCIziS7" transform="translate(0 0)" width="122.67217843649964px"/></g></svg>)
" height="150.90560294117645px" id="jxii70vzV" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(24.37 4.791)" width="261.37546588235216px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.728 3.018 L 116.384 4.988 L 123.793 7.455 L 130.373 10.224 L 136.629 13.481 L 142.286 17.103 L 147.097 20.91 L 151.356 25.179 L 154.784 29.643 L 157.336 34.117 L 159.104 38.936 L 159.995 43.657 L 159.981 48.672 L 159.104 53.438 L 157.336 58.222 L 154.784 62.73 L 151.356 67.194 L 147.128 71.41 L 142.286 75.271 L 136.629 78.892 L 130.373 82.149 L 123.686 84.945 L 116.384 87.386 L 108.728 89.356 L 100.843 90.838 L 92.557 91.859 L 84.164 92.374 L 75.632 92.365 L 67.439 91.859 L 59.322 90.865 L 51.344 89.365 L 43.611 87.386 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.464 L 8.639 67.194 L 5.227 62.775 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.782 L 0.892 38.936 L 2.613 34.25 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.37355058823529px" id="LN6Mj2wjX" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.05 69.207)" width="159.99511058823543px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.729 3.018 L 116.383 4.988 L 123.794 7.455 L 130.374 10.224 L 136.63 13.481 L 142.287 17.103 L 147.098 20.91 L 151.357 25.179 L 154.785 29.643 L 157.337 34.117 L 159.103 38.936 L 159.996 43.657 L 159.979 48.672 L 159.103 53.438 L 157.337 58.222 L 154.785 62.73 L 151.357 67.194 L 147.129 71.41 L 142.287 75.271 L 136.63 78.892 L 130.374 82.149 L 123.687 84.946 L 116.383 87.385 L 108.729 89.355 L 100.843 90.838 L 92.557 91.858 L 84.164 92.374 L 75.632 92.365 L 67.439 91.858 L 59.322 90.864 L 51.344 89.364 L 43.611 87.385 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.463 L 8.639 67.194 L 5.227 62.775 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.781 L 0.892 38.936 L 2.613 34.25 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.37427764705882px" id="jDPtsCydt" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.76 83.833)" width="159.99583764705716px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.728 3.018 L 116.384 4.988 L 123.793 7.455 L 130.373 10.224 L 136.629 13.481 L 142.286 17.103 L 147.097 20.91 L 151.356 25.179 L 154.784 29.643 L 157.336 34.117 L 159.104 38.936 L 159.995 43.657 L 159.981 48.672 L 159.104 53.438 L 157.336 58.222 L 154.784 62.73 L 151.356 67.194 L 147.128 71.41 L 142.286 75.271 L 136.629 78.892 L 130.373 82.149 L 123.686 84.945 L 116.384 87.386 L 108.728 89.356 L 100.843 90.838 L 92.557 91.859 L 84.164 92.374 L 75.632 92.365 L 67.439 91.859 L 59.322 90.865 L 51.344 89.365 L 43.611 87.386 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.464 L 8.639 67.194 L 5.227 62.775 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.782 L 0.892 38.936 L 2.613 34.25 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.37355058823529px" id="UKafYhxUp" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.05 69.207)" width="159.99511058823543px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.728 3.018 L 116.384 4.988 L 123.793 7.455 L 130.373 10.224 L 136.629 13.481 L 142.286 17.103 L 147.097 20.91 L 151.356 25.179 L 154.784 29.643 L 157.336 34.117 L 159.104 38.936 L 159.995 43.657 L 159.981 48.672 L 159.104 53.438 L 157.336 58.222 L 154.784 62.73 L 151.356 67.194 L 147.128 71.41 L 142.286 75.271 L 136.629 78.892 L 130.373 82.149 L 123.686 84.945 L 116.384 87.386 L 108.728 89.356 L 100.843 90.838 L 92.557 91.859 L 84.164 92.373 L 75.632 92.365 L 67.439 91.859 L 59.322 90.865 L 51.344 89.365 L 43.611 87.386 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.463 L 8.639 67.194 L 5.227 62.775 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.781 L 0.892 38.936 L 2.613 34.25 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.3733688235294px" id="BTS7eFR5p" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.05 48.404)" width="159.99511058823543px"/><path d="M 128.886 85.255 L 0 105.189 L 0 19.934 L 128.886 0 Z" fill="transparent" height="105.18923470588237px" id="XpYvdAzW3" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(57.724 4.311)" width="128.88608117646865px"/><path d="M 92.835 53.589 L 92.835 138.028 L 0 84.439 L 0 0 Z" fill="transparent" height="138.02757352941174px" id="K8lS4_UO3" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(192.202 5.927)" width="92.8345058823547px"/><path d="M 30.371 77.481 L 0 142.926 L 0 65.41 L 30.371 0 Z" fill="transparent" height="142.92631411764705px" id="ckGqTr2MB" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(21.656 34.705)" width="30.37088294117827px"/><path d="M 30.371 77.481 L 0 142.928 L 0 65.411 L 30.371 0 Z" fill="transparent" height="142.9275864705882px" id="r3233RfUB" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(254.683 70.769)" width="30.371064705883697px"/><path d="M 92.835 53.589 L 92.835 138.027 L 0 84.439 L 0 0 Z" fill="transparent" height="138.02721000000003px" id="LSrhVSYKp" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(21.656 104.548)" width="92.83486941176557px"/><path d="M 128.886 85.255 L 0 105.19 L 0 19.934 L 128.886 0 Z" fill="transparent" height="105.18959823529411px" id="x2Xopuli2" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="round" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(120.064 138.931)" width="128.88626294117825px"/><path d="M 29.623 10.224 L 36.309 7.429 L 43.611 4.988 L 51.344 3.009 L 59.322 1.509 L 67.439 0.515 L 75.693 0.009 L 84.164 0 L 92.557 0.515 L 100.919 1.544 L 108.728 3.017 L 116.384 4.988 L 123.793 7.455 L 130.373 10.224 L 136.629 13.481 L 142.286 17.103 L 147.097 20.91 L 151.356 25.179 L 154.784 29.643 L 157.336 34.116 L 159.104 38.936 L 159.995 43.657 L 159.981 48.672 L 159.104 53.438 L 157.336 58.221 L 154.784 62.73 L 151.356 67.194 L 147.128 71.41 L 142.286 75.271 L 136.629 78.892 L 130.373 82.149 L 123.686 84.945 L 116.384 87.385 L 108.728 89.356 L 100.843 90.838 L 92.557 91.859 L 84.164 92.373 L 75.632 92.364 L 67.439 91.859 L 59.322 90.865 L 51.344 89.365 L 43.611 87.385 L 36.233 84.918 L 29.623 82.149 L 23.351 78.883 L 17.709 75.271 L 12.928 71.463 L 8.639 67.194 L 5.227 62.774 L 2.613 58.124 L 0.892 53.438 L 0 48.592 L 0 43.781 L 0.892 38.936 L 2.613 34.249 L 5.227 29.599 L 8.639 25.179 L 12.867 20.963 L 17.709 17.103 L 23.351 13.49 Z" fill="rgb(0, 53, 51)" height="92.3733688235294px" id="dtqTIoHPq" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.69" stroke="rgb(180, 209, 63)" transform="translate(75.05 30.156)" width="159.99511058823543px"/></svg>)
" width="309px"><path d="M 0 0 C 62.424 52.356 97.323 76.699 124.122 133.612 C 125.774 137.121 129.275 139.414 133.153 139.414 L 178.332 139.414 C 182.27 139.414 185.824 137.027 187.434 133.433 C 220.347 59.939 255.786 56.508 309 0 C 223.902 11.24 92.218 13.79 0 0 Z" fill="rgb(244, 255, 200)" height="139.41414141414143px" id="YPPdTHgjp" width="309px"/></g></svg>)
" width="291.547144895145px"><path d="M 2.159 40.336 L 81.816 193.109 C 85.087 199.382 91.575 203.316 98.649 203.316 L 199.157 203.316 C 206.445 203.316 213.09 199.143 216.257 192.578 L 289.654 40.384 C 294.95 29.401 288.66 16.33 276.702 13.944 C 186.518 -4.05 102.962 -5.096 14.535 13.537 C 2.503 16.072 -3.526 29.434 2.159 40.336 Z" fill="rgb(174, 218, 0)" height="203.31595618278868px" id="beF0XCFO6" transform="translate(0 0)" width="291.54714489452647px"/></g></svg>)
" width="279.949712674067px"><path d="M 1.851 35.23 L 64.467 192.416 C 68.34 202.139 77.749 208.518 88.214 208.518 L 194.612 208.518 C 205.187 208.518 214.67 202.007 218.469 192.138 L 278.208 36.927 C 285.378 18.296 269.348 -1.055 249.578 1.717 C 168.185 13.131 109.4 10.303 29.167 0.211 C 9.712 -2.236 -5.406 17.013 1.851 35.23 Z" fill="rgb(145, 181, 0)" height="208.51809526570761px" id="tGoxWLGVd" transform="translate(0 0)" width="279.94971259877605px"/></g></svg>)
Recommended Blogs






























