
Potpie'S METRICS
Benchmarking AI Coding Tools in Production Environments
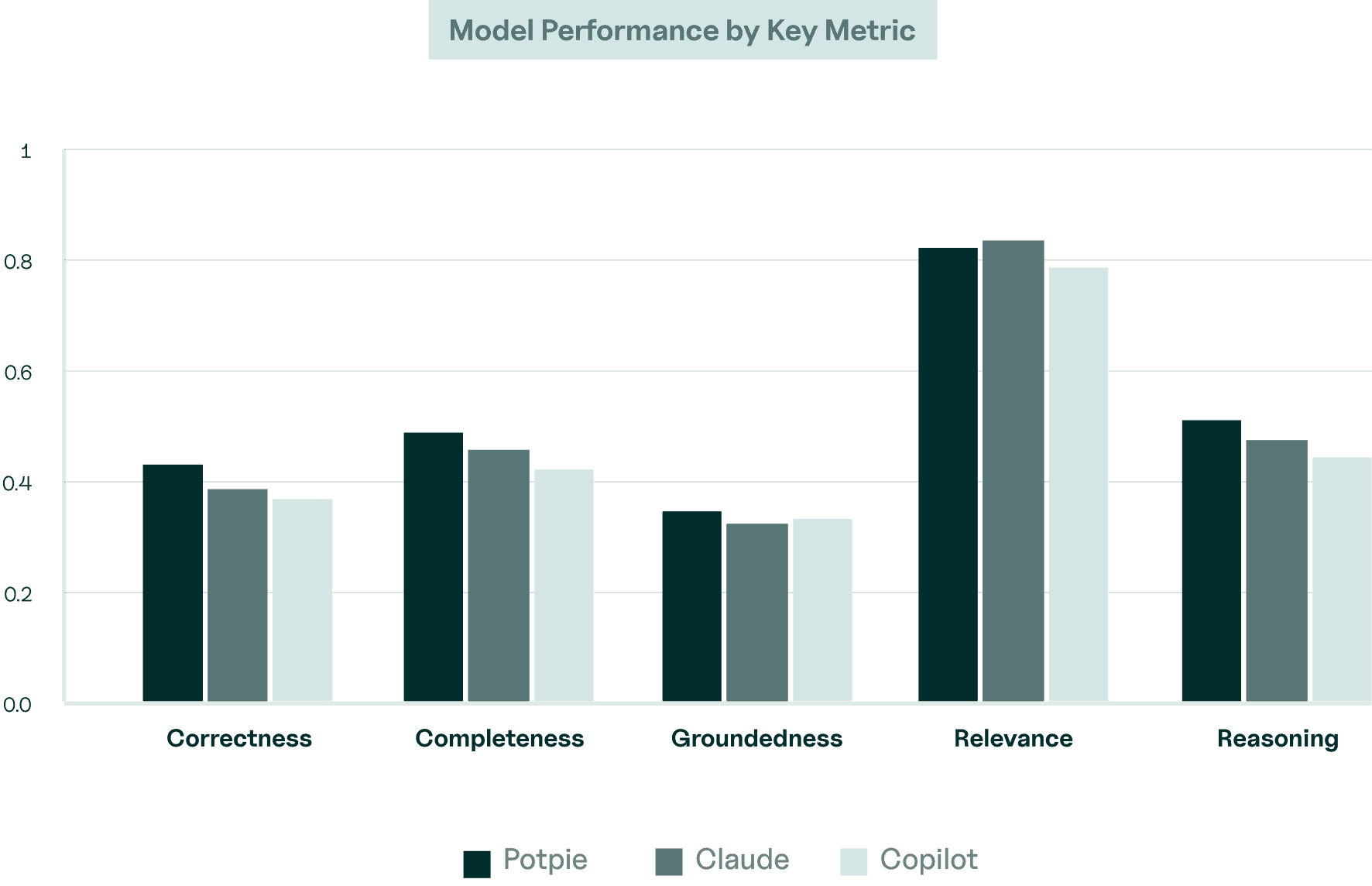
Tested against real-world queries across five large open-source codebases, Potpie sets a new benchmark in AI-driven code analysis.
" height="171.66666666666666px" id="gMI0SlmfZ" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="5.72" stroke="rgb(104, 154, 16)" transform="translate(5.723 3.167)" width="297.33524999999673px"/></svg>)
" height="170.4255319148936px" id="kA3lkAnGm" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="3.79" stroke="rgb(104, 154, 16)" transform="translate(2.267 3.787)" width="98.39518085106621px"/></svg>)
" height="170.4255319148936px" id="iftfqTrI5" stroke-dasharray="" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="3.79" stroke="rgb(104, 154, 16)" transform="translate(2.267 3.787)" width="98.39518085106275px"/></svg>)
Overview
We evaluate multiple AI code understanding agents across a set of curated questions drawn from real-world repositories to highlight practical differences in how they retrieve context, reason across files, and explain code behavior. The goal is to surface how well each agent handles tasks that resemble everyday developer queries.
Each agent is evaluated using default configurations with no additional tuning or repository-specific customization. We measure answer accuracy, reasoning quality, context retrieval, and consistency across queries to reflect how these systems perform in realistic development workflows.
Methodology
For QA benchmark, we selected repositories that represented real-world software complexity and workflows. The chosen repos are very popular open source projects with active development history, meaningful dependency structures, and diverse code patterns so agents must reason across files, modules, and context.